
CV |
Bio |
Google Scholar |
I am Raj Reddy Assistant Professor at Carnegie Mellon University in the School of Computer Science. I am a member of the Robotics Institute and affiliated to Machine Learning Department. I work in Artificial Intelligence at the intersection of Computer Vision, Machine Learning & Robotics. Previously, I spent a year as researcher at Meta AI Research collaborating with Jitendra Malik and visiting PostDoc at UC Berkeley with Pieter Abbeel. I received my PhD from UC Berkeley advised by Alyosha Efros & Trevor Darrell, and my Bachelors in Computer Science from IIT Kanpur. Prospective students: If you want to join CMU as PhD student, just mention my name in your application. Otherwise, if you would like to join our group in any other capacity, please fill this form and then send me a short email note without any documents. |
|
|
Our group studies Artificial Intelligence at the intersection of Computer Vision, Machine Learning & Robotics. Our ultimate goal is to build agents with a human-like ability to generalize in real and diverse environments. We believe understanding how to continually develop knowledge and acquire new skills from just raw sensory data will play a vital role in achieving this goal. Our group draws inspiration from psychology to build practical systems at the interface of vision, learning and robotics that can learn using data as its own supervision. If you would like to join our group, please fill this form and then send me a short email note without any documents.
| |
|
PhD Students Ananye Agarwal Lili Chen Alex Li Russell Mendonca Mihir Prabhudesai (with Katerina Fragkiadaki) Kenny Shaw |
Postdoc Unnat Jain MS Students Jayesh Singla Jim Yang Yulong Li Kexin Shi (visiting) |
|
Affiliates and Collaborators Murtaza Dalal, Danijar Hafner, Ronghang Hu, Ashish Kumar, Igor Mordatch, Oleh Rybkin |
|
|
Former Students Shikhar Bahl (PhD student, founding team at Skild AI) Alexandre Kirchmeyer (MS student, now PhD student at Princeton) Shagun Uppal (PhD student, now at Skild AI) Haoyu Xiong (MS student, now at Stanford) Shivam Duggal (MS student, now PhD student at MIT) Ellis Brown (MS student, now PhD student at NYU) Xuxin Cheng (MS student, now PhD student at UCSD) Aditya Kannan (Ugrad student, now at Hudson River Trading) Zipeng Fu (MS student, now PhD student at Stanford) Wenlong Huang (UGrad student, now PhD student at Stanford) Hongyu Wen (UGrad intern, now PhD student at Princeton) Boyuan Chen (UGrad student, now PhD student at MIT) Aravind Sivakumar (MS student, now startup founder) Ankit Ramchandani (MS student, now at Facebook) Pratyusha Sharma (UGrad intern, now PhD student at MIT) Dian Chen (UGrad student, now PhD student at UT Austin) | |
| 16-884: Deep Learning for Robotics (Fall 2022) 16-824: Visual Learning and Recognition (Spring 2022) 16-884: Learning for Embodied Action and Perception (Fall 2021) 16-824: Visual Learning and Recognition (Spring 2021) |
last update: Jan 2024 |
|
webpage |
abstract |
bibtex |
arXiv |
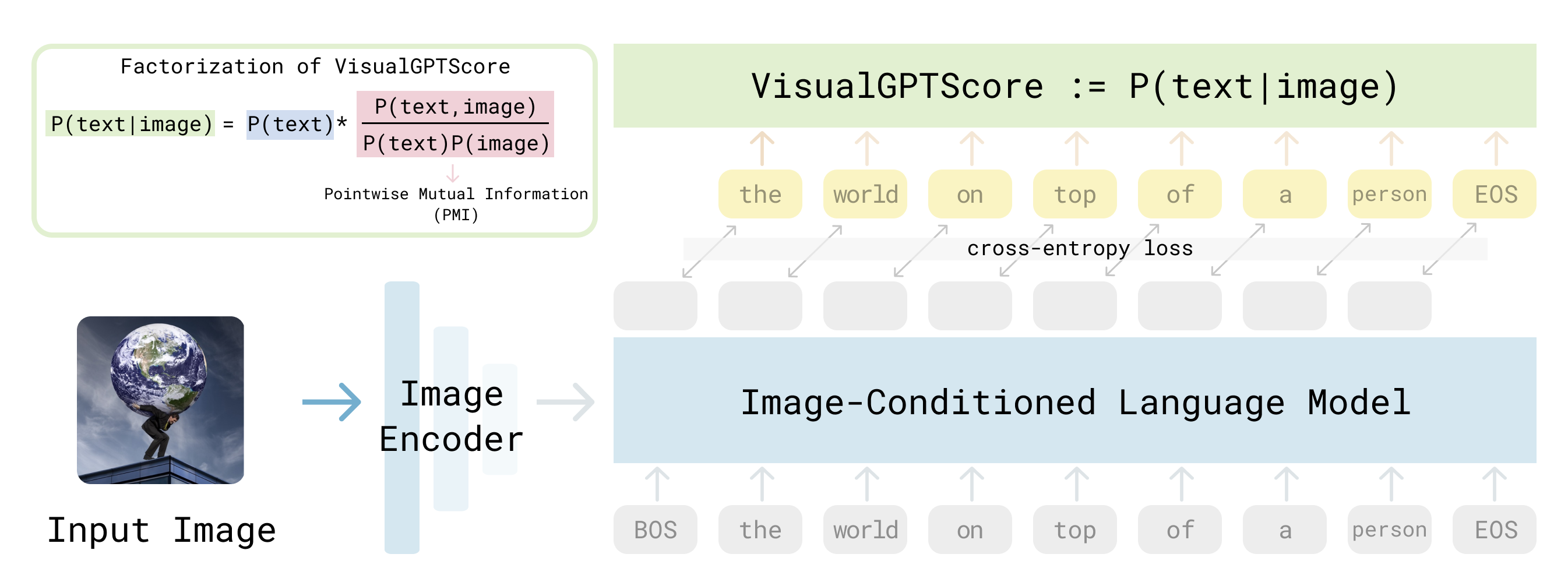
Vision-language models (VLMs) are impactful in part because they can be applied to a variety of visual understanding tasks in a zero-shot fashion, without any fine-tuning. We study generative VLMs that are trained for next-word generation given an image. We explore their zero-shot performance on the illustrative task of image-text retrieval across 8 popular vision-language benchmarks. Our first observation is that they can be repurposed for discriminative tasks (such as image-text retrieval) by simply computing the match score of generating a particular text string given an image. We call this probabilistic score the Visual Generative Pre-Training Score (VisualGPTScore). While the VisualGPTScore produces near-perfect accuracy on some retrieval benchmarks, it yields poor accuracy on others. We analyze this behavior through a probabilistic lens, pointing out that some benchmarks inadvertently capture unnatural language distributions by creating adversarial but unlikely text captions. In fact, we demonstrate that even a "blind" language model that ignores any image evidence can sometimes outperform all prior art, reminiscent of similar challenges faced by the visual-question answering (VQA) community many years ago. We derive a probabilistic post-processing scheme that controls for the amount of linguistic bias in generative VLMs at test time without having to retrain or fine-tune the model. We show that the VisualGPTScore, when appropriately debiased, is a strong zero-shot baseline for vision-language understanding, oftentimes producing state-of-the-art accuracy. |
|
webpage |
abstract |
bibtex |
arXiv |
code
Humans can perform parkour by traversing obstacles in a highly dynamic fashion requiring precise eye-muscle coordination and movement. Getting robots to do the same task requires overcoming similar challenges. Classically, this is done by independently engineering perception, actuation, and control systems to very low tolerances. This restricts them to tightly controlled settings such as a predetermined obstacle course in labs. In contrast, humans are able to learn parkour through practice without significantly changing their underlying biology. In this paper, we take a similar approach to developing robot parkour on a small low-cost robot with imprecise actuation and a single front-facing depth camera for perception which is low-frequency, jittery, and prone to artifacts. We show how a single neural net policy operating directly from a camera image, trained in simulation with largescale RL, can overcome imprecise sensing and actuation to output highly precise control behavior end-to-end. We show our robot can perform a high jump on obstacles 2x its height, long jump across gaps 2x its length, do a handstand and run across tilted ramps, and generalize to novel obstacle courses with different physical properties. |
|
|
webpage |
abstract |
bibtex |
arXiv
Modeling and simulating soft robot hands can aid in design iteration for complex and high degree-of-freedom (DoF) morphologies. This can be further supplemented by iterating on the design based on its performance in real world manipulation tasks. However, iterating in the real world requires a framework that allows us to test new designs quickly at low costs. In this paper, we present a framework that leverages rapid prototyping of the hand using 3D-printing, and utilizes teleoperation to evaluate the hand in real world manipulation tasks. Using this framework, we design a 3D-printed 16-DoF dexterous anthropomorphic soft hand (DASH) and iteratively improve its design over five iterations. Rapid prototyping techniques such as 3D-printing allow us to directly evaluate the fabricated hand without modeling it in simulation. We show that the design improves over five design iterations through evaluating the hand’s performance in 30 real-world teleoperated manipulation tasks. Testing over 900 demonstrations shows that our final version of DASH can solve 19 of the 30 tasks compared to Allegro, a popular rigid hand in the market, which can only solve 7 tasks. We open-source our CAD models as well as the teleoperated dataset for further study. |
|
|
webpage |
abstract |
bibtex |
arXiv
While there have been significant strides in dexterous manipulation, most of it is limited to benchmark tasks like in-hand reorientation which are of limited utility in the real world. The main benefit of dexterous hands over two-fingered ones is their ability to pickup tools and other objects (including thin ones) and grasp them firmly to apply force. However, this task requires both a complex understanding of functional affordances as well as precise low-level control. While prior work obtains affordances from human data this approach doesn't scale to low-level control. Similarly, simulation training cannot give the robot an understanding of real-world semantics. In this paper, we aim to combine the best of both worlds to accomplish functional grasping for in-the-wild objects. We use a modular approach. First, affordances are obtained by matching corresponding regions of different objects and then a low-level policy trained in sim is run to grasp it. We propose a novel application of eigengrasps to reduce the search space of RL using a small amount of human data and find that it leads to more stable and physically realistic motion. We find that eigengrasp action space beats baselines in simulation and outperforms hardcoded grasping in real and matches or outperforms a trained human teleoperator. |
|
|
webpage |
abstract |
bibtex |
arXiv
Learning from unstructured and uncurated data has become the dominant paradigm for generative approaches in language or vision. Such unstructured and unguided behavior data, commonly known as play, is also easier to collect in robotics but much more difficult to learn from due to its inherently multimodal, noisy, and suboptimal nature. In this paper, we study this problem of learning goal-directed skill policies from unstructured play data which is labeled with language in hindsight. Specifically, we leverage advances in diffusion models to learn a multi-task diffusion model to extract robotic skills from play data. Using a conditional denoising diffusion process in the space of states and actions, we can gracefully handle the complexity and multimodality of play data and generate diverse and interesting robot behaviors. To make diffusion models more useful for skill learning, we encourage robotic agents to acquire a vocabulary of skills by introducing discrete bottlenecks into the conditional behavior generation process. In our experiments, we demonstrate the effectiveness of our approach across a wide variety of environments in both simulation and the real world. |
|
|
webpage |
abstract |
bibtex |
CoRL
Dexterity is often seen as a cornerstone of complex manipulation. Humans are able to perform a host of skills with their hands, from making food to operating tools. In this paper, we investigate these challenges, especially in the case of soft, deformable objects as well as complex, relatively long-horizon tasks. Although, learning such behaviors from scratch can be data inefficient. To circumvent this, we propose a novel approach, DEFT (DExterous Fine-Tuning for Hand Policies), that leverages human-driven priors, which are executed directly in the real world. In order to improve upon these priors, DEFT involves an efficient online optimization procedure. With the integration of human-based learning and online fine-tuning, coupled with a soft robotic hand, DEFT demonstrates success across various tasks, establishing a robust, data-efficient pathway toward general dexterous manipulation. |
|

|
webpage |
abstract |
bibtex |
arXiv |
code
The recent wave of large-scale text-to-image diffusion models has dramatically increased our text-based image generation abilities. These models can generate realistic images for a staggering variety of prompts and exhibit impressive compositional generalization abilities. Almost all use cases thus far have solely focused on sampling; however, diffusion models can also provide conditional density estimates, which are useful for tasks beyond image generation. In this paper, we show that the density estimates from large-scale text-to-image diffusion models like Stable Diffusion can be leveraged to perform zero-shot classification without any additional training. Our generative approach to classification, which we call Diffusion Classifier, attains strong results on a variety of benchmarks and outperforms alternative methods of extracting knowledge from diffusion models. Although a gap remains between generative and discriminative approaches on zero-shot recognition tasks, we find that our diffusion-based approach has stronger multimodal relational reasoning abilities than competing discriminative approaches. Finally, we use Diffusion Classifier to extract standard classifiers from class-conditional diffusion models trained on ImageNet. Even though these models are trained with weak augmentations and no regularization, they approach the performance of SOTA discriminative classifiers. Overall, our results are a step toward using generative over discriminative models for downstream tasks. |

|
webpage |
abstract |
bibtex |
arXiv |
code |
video
Modern vision models typically rely on finetuning general-purpose models pretrained on large, static datasets. These general-purpose models only capture the knowledge within their pretraining datasets, which are tiny, out-of-date snapshots of the Internet—where billions of images are uploaded each day. We suggest an alternate approach: rather than hoping our static datasets transfer to our desired tasks after large-scale pretraining, we propose dynamically utilizing the Internet to quickly train a small-scale model that does extremely well on the task at hand. Our approach, called Internet Explorer, explores the web in a self-supervised manner to progressively find relevant examples that improve performance on a desired target dataset. It cycles between searching for images on the Internet with text queries, self-supervised training on downloaded images, determining which images were useful, and prioritizing what to search for next. We evaluate Internet Explorer across several datasets and show that it outperforms or matches CLIP oracle performance by using just a single GPU desktop to actively query the Internet for 30–40 hours. |
|
webpage |
abstract |
bibtex |
arXiv |
code |
talk video
Current visual detectors, though impressive within their training distribution, often fail to parse out-of-distribution scenes into their constituent entities. Recent test-time adaptation methods use auxiliary self-supervised losses to adapt the network parameters to each test example independently and have shown promising results towards generalization outside the training distribution for the task of image classification. In our work, we find evidence that these losses are insufficient for the task of scene decomposition, without also considering architectural inductive biases. Recent slot-centric generative models attempt to decompose scenes into entities in a self-supervised manner by reconstructing pixels. Drawing upon these two lines of work, we propose Slot-TTA, a semi-supervised slot-centric scene decomposition model that at test time is adapted per scene through gradient descent on reconstruction or cross-view synthesis objectives. We evaluate Slot-TTA across multiple input modalities, images or 3D point clouds, and show substantial out-of-distribution performance improvements against state-of-the-art supervised feed-forward detectors, and alternative test-time adaptation methods. |
|

|
webpage |
abstract |
bibtex |
pdf
Agents that are aware of the separation between the environments and themselves can leverage this understanding to form effective representations of visual input. We propose an approach for learning such structured representations for RL algorithms, using visual knowledge of the agent, which is often inexpensive to obtain, such as its shape or mask. This is incorporated into the RL objective using a simple auxiliary loss. We show that our method, SEAR (Structured Environment-Agent Representations), outperforms state-of-the-art model-free approaches over 18 different challenging visual simulation environments spanning 5 different robots. |
|
webpage |
abstract |
bibtex |
RSS
Dexterous manipulation has been a long-standing challenge in robotics. While machine learning techniques have shown some promise, results have largely been currently limited to simulation. This can be mostly attributed to the lack of suitable hardware. In this paper, we present LEAP Hand, a low-cost dexterous and anthropomorphic hand for machine learning research. In contrast to previous hands, LEAP Hand has a novel kinematic structure that allows maximal dexterity regardless of finger pose. LEAP Hand is low-cost and can be assembled in 4 hours at a cost of 2000 USD from readily available parts. It is capable of consistently exerting large torques over long durations of time. We show that LEAP Hand can be used to perform several manipulation tasks in the real world—from visual teleoperation to learning from passive video data and sim2real. LEAP Hand significantly outperforms its closest competitor Allegro Hand in all our experiments while being 1/8th of the cost. We release the URDF model, 3D CAD files, tuned simulation environment, and a development platform with useful APIs on our website. |
|
|
webpage |
abstract |
bibtex |
arXiv
We tackle the problem of learning complex, general behaviors directly in the real world. We propose an approach for robots to efficiently learn manipulation skills using only a handful of real-world interaction trajectories from many different settings. Inspired by the success of learning from large-scale datasets in the fields of computer vision and natural language, our belief is that in order to efficiently learn, a robot must be able to leverage internet-scale, human video data. Humans interact with the world in many interesting ways, which can allow a robot to not only build an understanding of useful actions and affordances but also how these actions affect the world for manipulation. Our approach builds a structured, human-centric action space grounded in visual affordances learned from human videos. Further, we train a world model on human videos and fine-tune on a small amount of robot interaction data without any task supervision. We show that this approach of affordance-space world models enables different robots to learn various manipulation skills in complex settings, in under 30 minutes of interaction. |
|
|
webpage |
abstract |
bibtex |
arXiv
Building a robot that can understand and learn to interact by watching humans has inspired several vision problems. However, despite some successful results on static datasets, it remains unclear how current models can be used on a robot directly. In this paper, we aim to bridge this gap by leveraging videos of human interactions in an environment centric manner. Utilizing internet videos of human behavior, we train a visual affordance model that estimates where and how in the scene a human is likely to interact. The structure of these behavioral affordances directly enables the robot to perform many complex tasks. We show how to seamlessly integrate our affordance model with four robot learning paradigms including offline imitation learning, exploration, goal-conditioned learning, and action parameterization for reinforcement learning. We show the efficacy of our approach, which we call Vision-Robotics Bridge (VRB) as we aim to seamlessly integrate computer vision techniques with robotic manipulation, across 4 real world environments, over 10 different tasks, and 2 robotic platforms operating in the wild. |
|

|
webpage |
abstract |
bibtex |
arXiv
The ability to quickly learn a new task with minimal instruction - known as few-shot learning - is a central aspect of intelligent agents. Classical few-shot benchmarks make use of few-shot samples from a single modality, but such samples may not be sufficient to characterize an entire concept class. In contrast, humans use cross-modal information to learn new concepts efficiently. In this work, we demonstrate that one can indeed build a better visual dog classifier by reading about dogs and listening to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP are inherently cross-modal, mapping different modalities to the same representation space. Specifically, we propose a simple cross-modal adaptation approach that learns from few-shot examples spanning different modalities. By repurposing class names as additional one-shot training samples, we achieve SOTA results with an embarrassingly simple linear classifier for vision-language adaptation. Furthermore, we show that our approach can benefit existing methods such as prefix tuning, adapters, and classifier ensembling. Finally, to explore other modalities beyond vision and language, we construct the first (to our knowledge) audiovisual few-shot benchmark and use cross-modal training to improve the performance of both image and audio classification. |
|
webpage |
abstract |
bibtex |
arXiv |
demo |
in the media
Locomotion has seen dramatic progress for walking or running across challenging terrains. However, robotic quadrupeds are still far behind their biological counterparts, such as dogs, which display a variety of agile skills and can use the legs beyond locomotion to perform several basic manipulation tasks like interacting with objects and climbing. In this paper, we take a step towards bridging this gap by training quadruped robots not only to walk but also to use the front legs to climb walls, press buttons, and perform object interaction in the real world. To handle this challenging optimization, we decouple the skill learning broadly into locomotion, which involves anything that involves movement whether via walking or climbing a wall, and manipulation, which involves using one leg to interact while balancing on the other three legs. These skills are trained in simulation using curriculum and transferred to the real world using our proposed sim2real variant that builds upon recent locomotion success. Finally, we combine these skills into a robust long-term plan by learning a behavior tree that encodes a high-level task hierarchy from one clean expert demonstration. We evaluate our method in both simulation and real-world showing successful executions of both short as well as long-range tasks and how robustness helps confront external perturbations. |
|
|
webpage |
abstract |
bibtex |
arXiv
Robotic agents that operate autonomously in the real world need to continuously explore their environment and learn from the data collected, with minimal human supervision. While it is possible to build agents that can learn in such a manner without supervision, current methods struggle to scale to the real world. Thus, we propose ALAN, an autonomously exploring robotic agent, that can perform many tasks in the real world with little training and interaction time. This is enabled by measuring environment change, which reflects object movement and ignores changes in the robot position. We use this metric directly as an environment-centric signal, and also maximize the uncertainty of predicted environment change, which provides agent-centric exploration signal. We evaluate our approach on two different real-world play kitchen settings, enabling a robot to efficiently explore and discover manipulation skills, and perform tasks specified via goal images. |
|
 |
webpage |
pdf |
abstract |
bibtex |
code |
demo video
A majority of approaches solve the problem of video frame interpolation by computing bidirectional optical flow between adjacent frames of a video followed by a suitable warping algorithm to generate the output frames. However, methods relying on optical flow often fail to model occlusions and complex non-linear motions directly from the video and introduce additional bottlenecks unsuitable for real time deployment. To overcome these limitations, we propose a flexible and efficient architecture that makes use of 3D space-time convolutions to enable end to end learning and inference for the task of video frame interpolation. Our method efficiently learns to reason about non-linear motions, complex occlusions and temporal abstractions resulting in improved performance on video interpolation, while requiring no additional inputs in the form of optical flow or depth maps. We evaluate our model on a wide range of challenging settings and consistently demonstrate superior qualitative and quantitative results compared with current methods on various popular benchmarks including Vimeo-90K, UCF101, DAVIS, Adobe, and GoPro. Finally, we demonstrate that video frame interpolation can serve as a useful self-supervised pretext task for action recognition, optical flow estimation, and motion magnification.
@article{kalluri2020flavr,
author = {Kalluri, Tarun and
Pathak, Deepak and
Chandraker, Manmohan and Tran, Du},
title = {FLAVR: Flow-Agnostic
Video Representations
for Fast Frame Interpolation},
journal={WACV},
year = {2023}
}
|
|
webpage |
abstract |
bibtex |
arXiv |
demo |
in the media
Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world and is able to run in real-time on the limited compute of the robot. It can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain. |
|
|
webpage |
abstract |
bibtex |
arXiv |
demo |
in the media
An attached arm can significantly increase the applicability of legged robots to several mobile manipulation tasks that are not possible for the wheeled or tracked counterparts. The standard control pipeline for such legged manipulators is to decouple the controller into that of manipulation and locomotion. However, this is ineffective and requires immense engineering to support coordination between the arm and legs, error can propagate across modules causing non-smooth unnatural motions. It is also biological implausible where there is evidence for strong motor synergies across limbs. In this work, we propose to learn a unified policy for whole-body control of a legged manipulator using reinforcement learning. We propose Regularized Online Adaptation to bridge the Sim2Real gap for high-DoF control, and Advantage Mixing exploiting the causal dependency in the action space to overcome local minima during training the whole-body system. We also present a simple design for a low-cost legged manipulator, and find that our unified policy can demonstrate dynamic and agile behaviors across several task setups. |
|
|
webpage |
abstract |
bibtex |
arXiv |
demo
To build general robotic agents that can operate in many environments, it is often imperative for the robot to collect experience in the real world. However, this is often not feasible due to safety, time and hardware restrictions. We thus propose leveraging the next best thing as real world experience: internet videos of humans using their hands. Visual priors, such as visual features, are often learned from videos, but we believe that more information from videos can be utilized as a stronger prior. We build a learning algorithm, VideoDex, that leverages visual, action and physical priors from human video datasets to guide robot behavior. These action and physical priors in the neural network dictate the typical human behavior for a particular robot task. We test our approach on a robot arm and dexterous hand based system and show strong results on many different manipulation tasks, outperforming various state-of-the-art methods. |
|

|
webpage |
abstract |
bibtex |
arXiv
The ability to learn from human demonstration endows robots with the ability to automate various tasks. However, directly learning from human demonstration is challenging since the structure of the human hand can be very different from the desired robot gripper. In this work, we show that manipulation skills can be transferred from a human to a robot through the use of micro-evolutionary reinforcement learning, where a five-finger human dexterous hand robot gradually evolves into a commercial robot, while repeated interacting in a physics simulator to continuously update the policy that is first learned from human demonstration. To deal with the high dimensions of robot parameters, we propose an algorithm for multi-dimensional evolution path searching that allows joint optimization of both the robot evolution path and the policy. Through experiments on human object manipulation datasets, we show that our framework can efficiently transfer the expert human agent policy trained from human demonstrations in diverse modalities to target commercial robots. |

|
webpage |
abstract |
bibtex |
arXiv
Lifelong learners must recognize concept vocabularies that evolve over time. A common yet underexplored scenario is learning with class labels that continually refine/expand old classes. For example, humans learn to recognize dog before dog breeds. In practical settings, dataset versioning often introduces refinement to ontologies, such as autonomous vehicle benchmarks that refine a previous vehicle class into school-bus as autonomous operations expand to new cities. This paper formalizes a protocol for studying the problem of Learning with Evolving Class Ontology (LECO). LECO requires learning classifiers in distinct time periods (TPs); each TP introduces a new ontology of “fine” labels that refines old ontologies of “coarse” labels (e.g., dog breeds that refine the previous dog). LECO explores such questions as whether to annotate new data or relabel the old, how to exploit coarse labels, and whether to finetune the previous TP’s model or train from scratch. To answer these questions, we leverage insights from related problems such as class-incremental learning. We validate them under the LECO protocol through the lens of image classification (on CIFAR and iNaturalist) and semantic segmentation (on Mapillary). Extensive experiments lead to some surprising conclusions; while the current status quo in the field is to relabel existing datasets with new class ontologies (such as COCO-to-LVIS or Mapillary1.2-to-2.0), LECO demonstrates that a far better strategy is to annotate new data with the new ontology. However, this produces an aggregate dataset with inconsistent old-vs-new labels, complicating learning. To address this challenge, we adopt methods from semi-supervised and partial-label learning. We demonstrate that such strategies can surprisingly be made near-optimal, in the sense of approaching an “oracle” that learns on the aggregate dataset exhaustively labeled with the newest ontology. |

|
webpage |
abstract |
bibtex |
arXiv |
demo |
in the media
We approach the problem of learning by watching humans in the wild. While traditional approaches in Imitation and Reinforcement Learning are promising for learning in the real world, they are either sample inefficient or are constrained to lab settings. Meanwhile, there has been a lot of success in processing passive, unstructured human data. We propose tackling this problem via an efficient one-shot robot learning algorithm, centered around learning from a third person perspective. We call our method WHIRL: In the Wild Human-Imitated Robot Learning. In WHIRL, we aim to use human videos to extract a prior over the intent of the demonstrator, and use this to initialize our agent's policy. We introduce an efficient real-world policy learning scheme, that improves over the human prior using interactions. Our key contributions are a simple sampling-based policy optimization approach, a novel objective function for aligning human and robot videos as well as an exploration method to boost sample efficiency. We show, one-shot, generalization and success in real world settings, including 20 different manipulation tasks in the wild.
@article{whirl,
title={Human-to-Robot Imitation in
the Wild},
author={Bahl, Shikhar and Gupta,
Abhinav and Pathak, Deepak},
journal={RSS},
year={2022}
}
|

|
webpage |
abstract |
bibtex |
arXiv |
demo |
in the media
We build a system that enables any human to control a robot hand and arm, simply by demonstrating motions with their own hand. The robot observes the human operator via a single RGB camera and imitates their actions in real-time. Human hands and robot hands differ in shape, size, and joint structure, and performing this translation from a single uncalibrated camera is a highly underconstrained problem. Moreover, the retargeted trajectories must effectively execute tasks on a physical robot, which requires them to be temporally smooth and free of self-collisions. Our key insight is that while paired human-robot correspondence data is expensive to collect, the internet contains a massive corpus of rich and diverse human hand videos. We leverage this data to train a system that understands human hands and retargets a human video stream into a robot hand-arm trajectory that is smooth, swift, safe, and semantically similar to the guiding demonstration. We demonstrate that it enables previously untrained people to teleoperate a robot on various dexterous manipulation tasks. Our low-cost, glove-free, marker-free remote teleoperation system makes robot teaching more accessible and we hope that it can aid robots that learn to act autonomously in the real world.
@article{telekinesis,
title={Robotic Telekinesis: Learning a
Robotic Hand Imitator by Watching Humans
on Youtube},
author={Sivakumar, Aravind and
Shaw, Kenneth and Pathak, Deepak},
journal={RSS},
year={2022}
}
|

|
webpage |
abstract |
bibtex |
arXiv |
demo
Recent advances in legged locomotion have enabled quadrupeds to walk on challenging terrains. However, bipedal robots are inherently more unstable and hence it's harder to design walking controllers for them. In this work, we leverage recent advances in rapid adaptation for locomotion control, and extend them to work on bipedal robots. Similar to existing works, we start with a base policy which produces actions while taking as input an estimated extrinsics vector from an adaptation module. This extrinsics vector contains information about the environment and enables the walking controller to rapidly adapt online. However, the extrinsics estimator could be imperfect, which might lead to poor performance of the base policy which expects a perfect estimator. In this paper, we propose A-RMA (Adapting RMA), which additionally adapts the base policy for the imperfect extrinsics estimator by finetuning it using model-free RL. We demonstrate that A-RMA outperforms a number of RL-based baseline controllers and model-based controllers in simulation, and show zero-shot deployment of a single A-RMA policy to enable a bipedal robot, Cassie, to walk in a variety of different scenarios in the real world beyond what it has seen during training.
@article{arma,
title={Adapting Rapid Motor
Adaptation for Bipedal Robots},
author={Kumar, Ashish and Li,
Zhongyu and Zeng, Jun and Pathak,
Deepak and Sreenath, Koushil
and Malik, Jitendra},
journal={IROS},
year={2022}
}
|

|
pdf |
abstract |
bibtex |
arXiv
Contrastive methods have led a recent surge in the performance of self-supervised representation learning (SSL). Recent methods like BYOL or SimSiam purportedly distill these contrastive methods down to their essence, removing bells and whistles, including the negative examples, that do not contribute to downstream performance. These "non-contrastive" methods surprisingly work well without using negatives even though the global minimum lies at trivial collapse. We empirically analyze these non-contrastive methods and find that SimSiam is extraordinarily sensitive to model size. In particular, SimSiam representations undergo partial dimensional collapse if the model is too small relative to the dataset size. We propose a metric to measure the degree of this collapse and show that it can be used to forecast the downstream task performance without any fine-tuning or labels. We further analyze architectural design choices and their effect on the downstream performance. Finally, we demonstrate that shifting to a continual learning setting acts as a regularizer and prevents collapse, and a hybrid between continual and multi-epoch training can improve linear probe accuracy by as many as 18 percentage points using ResNet-18 on ImageNet.
@article{SimSiamCollapse,
title={Understanding Collapse in
Non-Contrastive Siamese
Representation Learning},
author={Li, Alexander Cong and
Efros, Alexei A. and Pathak, Deepak},
journal={ECCV},
year={2022}
}
|

|
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
talk video
We present a new framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs.
@article{duggal2022tars3D,
author = {Duggal, Shivam and Pathak, Deepak},
title = {Topologically-Aware Deformation
Fields for Single-View 3D Reconstruction},
journal= {CVPR},
year = {2022}
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
demo video
Can world knowledge learned by large language models (LLMs) be used to act in interactive environments? In this paper, we investigate the possibility of grounding high-level tasks, expressed in natural language (e.g. "make breakfast"), to a chosen set of actionable steps (e.g. "open fridge"). While prior work focused on learning from explicit step-by-step examples of how to act, we surprisingly find that if pre-trained LMs are large enough and prompted appropriately, they can effectively decompose high-level tasks into low-level plans without any further training. However, the plans produced naively by LLMs often cannot map precisely to admissible actions. We propose a procedure that conditions on existing demonstrations and semantically translates the plans to admissible actions. Our evaluation in the recent VirtualHome environment shows that the resulting method substantially improves executability over the LLM baseline. The conducted human evaluation reveals a trade-off between executability and correctness but shows a promising sign towards extracting actionable knowledge from language models.
@article{huang2022language,
title={Language Models as Zero-Shot
Planners: Extracting Actionable Knowledge
for Embodied Agents},
author={Huang, Wenlong and Abbeel, Pieter and
Pathak, Deepak and Mordatch, Igor},
journal={ICML},
year={2022}
}
|

|
paper |
abstract |
bibtex
A popular paradigm in robotic learning is to train a policy from scratch for every new robot. This is not only inefficient but also often impractical for complex robots. In this work, we consider the problem of transferring a policy across two different robots with significantly different parameters such as kinematics and morphology. Existing approaches that train a new policy by matching the action or state transition distribution, including imitation learning methods, fail due to optimal action and/or state distribution being mismatched in different robots. In this paper, we propose a novel method named REvolveR of using continuous evolutionary models for robotic policy transfer implemented in a physics simulator. We interpolate between the source robot and the target robot by finding a continuous evolutionary change of robot parameters. An expert policy on the source robot is transferred through training on a sequence of intermediate robots that gradually evolve into the target robot. Experiments show that the proposed continuous evolutionary model can effectively transfer the policy across robots and achieve superior sample efficiency on new robots using a physics simulator. The proposed method is especially advantageous in sparse reward settings where exploration can be significantly reduced.
@article{liu2022revolver,
title={REvolveR: Continuous Evolutionary
Models for Robot-to-robot Policy Transfer},
author={Liu, Xingyu and Pathak, Deepak
and Kitani, Kris M},
journal={ICML},
year={2022}
}
|

|
pdf |
abstract |
bibtex |
arXiv
Reward signals in reinforcement learning are expensive to design and often require access to the true state which is not available in the real world. Common alternatives are usually demonstrations or goal images which can be labor-intensive to collect. On the other hand, text descriptions provide a general, natural, and low-effort way of communicating the desired task. However, prior works in learning text-conditioned policies still rely on rewards that are defined using either true state or labeled expert demonstrations. We use recent developments in building large-scale visuolanguage models like CLIP to devise a framework that generates the task reward signal just from goal text description and raw pixel observations which is then used to learn the task policy. We evaluate the proposed framework on control and robotic manipulation tasks. Finally, we distill the individual task policies into a single goal text conditioned policy that can generalize in a zero-shot manner to new tasks with unseen objects and unseen goal text descriptions.
@article{rewardspec,
title={Zero-Shot Reward Specification
via Grounded Natural Language},
author={Mahmoudieh, Parsa and Pathak,
Deepak and Darrell, Trevor},
journal={ICML},
year={2022}
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Dexterous manipulation of arbitrary objects, a fundamental daily task for humans, has been a grand challenge for autonomous robotic systems. Although data-driven approaches using reinforcement learning can develop specialist policies that discover behaviors to control a single object, they often exhibit poor generalization to unseen ones. In this work, we show that policies learned by existing reinforcement learning algorithms can in fact be generalist when combined with multi-task learning and a well-chosen object representation. We show that a single generalist policy can perform in-hand manipulation of over 100 geometrically-diverse real-world objects and generalize to new objects with unseen shape or size. Interestingly, we find that multi-task learning with object point cloud representations not only generalizes better but even outperforms the single-object specialist policies on both training as well as held-out test objects.
@article{huang2021geometry,
title={Generalization in Dexterous Manipulation
via Geometry-Aware Multi-Task Learning},
author={Huang, Wenlong and Mordatch, Igor and
Abbeel, Pieter and Pathak, Deepak},
journal={arXiv preprint arXiv:2111.03062},
year={2021}
}
|

|
webpage |
pdf |
abstract |
bibtex |
code |
benchmark |
talk video
How can artificial agents learn to solve wide ranges of tasks in complex visual environments in the absence of external supervision? We decompose this question into two problems, global exploration of the environment and learning to reliably reach situations found during exploration. We introduce the Latent Explorer Achiever (LEXA), a unified solution to these by learning a world model from the high-dimensional image inputs and using it to train an explorer and an achiever policy from imagined trajectories. Unlike prior methods that explore by reaching previously visited states, the explorer plans to discover unseen surprising states through foresight, which are then used as diverse targets for the achiever. After the unsupervised phase, LEXA solves tasks specified as goal images zero-shot without any additional learning. We introduce a challenging benchmark spanning across four standard robotic manipulation and locomotion domains with a total of over 40 test tasks. LEXA substantially outperforms previous approaches to unsupervised goal reaching, achieving goals that require interacting with multiple objects in sequence. Finally, to demonstrate the scalability and generality of LEXA, we train a single general agent across four distinct environments.
@inproceedings{mendonca2021lexa,
Author = {Mendonca, Russell and
Rybkin, Oleh and Daniilidis, Kostas and
Hafner, Danijar and Pathak, Deepak},
Title = {Discovering and Achieving
Goals via World Models},
Booktitle = {NeurIPS},
Year = {2021}
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
We propose a simple architecture for deep reinforcement learning that can control how quickly the network fits different frequencies in the training data. We explain this behavior using infinite-width analysis with the Neural Tangent Kernel, and use this to prioritize learning low-frequency functions and speed up learning by reducing networks' susceptibility to noise in the optimization process, such as during Bellman updates. Experiments on standard state-based and image-based RL benchmarks show clear sample-efficiency gains, as well as increased robustness to added bootstrap noise.
@inproceedings{li2021functional,
title={Functional Regularization for
Reinforcement Learning via Learned
Fourier Features},
author={Alexander Cong Li and
Deepak Pathak},
booktitle={NeurIPS},
year={2021}
}
|

|
pdf |
abstract |
bibtex |
arXiv |
code
Common approaches for task-agnostic exploration learn tabula-rasa --the agent assumes isolated environments and no prior knowledge or experience. However, in the real world, agents learn in many environments and always come with prior experiences as they explore new ones. Exploration is a lifelong process. In this paper, we propose a paradigm change in the formulation and evaluation of task-agnostic exploration. In this setup, the agent first learns to explore across many environments without any extrinsic goal in a task-agnostic manner. Later on, the agent effectively transfers the learned exploration policy to better explore new environments when solving tasks. In this context, we evaluate several baseline exploration strategies and present a simple yet effective approach to learning task-agnostic exploration policies. Our key idea is that there are two components of exploration: (1) an agent-centric component encouraging exploration of unseen parts of the environment based on an agent's belief; (2) an environment-centric component encouraging exploration of inherently interesting objects. We show that our formulation is effective and provides the most consistent exploration across several training-testing environment pairs. We also introduce benchmarks and metrics for evaluating task-agnostic exploration strategies.
@inproceedings{parisi21interesting,
title={Interesting Object, Curious Agent:
Learning Task-Agnostic Exploration},
author={Parisi, Simone and Dean, Victoria
and Pathak, Deepak and Gupta, Abhinav},
booktitle={NeurIPS},
year={2021}
}
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
Despite the potential of reinforcement learning (RL) for building general-purpose robotic systems, training RL agents to solve robotics tasks still remains challenging due to the difficulty of exploration in purely continuous action spaces. Addressing this problem is an active area of research with the majority of focus on improving RL methods via better optimization or more efficient exploration. An alternate but important component to consider improving is the interface of the RL algorithm with the robot. In this work, we manually specify a library of robot action primitives (RAPS), parameterized with arguments that are learned by an RL policy. These parameterized primitives are expressive, simple to implement, enable efficient exploration and can be transferred across robots, tasks and environments. We perform a thorough empirical study across challenging tasks in three distinct domains with image input and a sparse terminal reward. We find that our simple change to the action interface substantially improves both the learning efficiency and task performance irrespective of the underlying RL algorithm, significantly outperforming prior methods which learn skills from offline expert data.
@inproceedings{dalal2021raps,
Author = {Dalal, Murtaza and Pathak, Deepak
and Salakhutdinov, Ruslan},
Title = {Accelerating Robotic Reinforcement
Learning via Parameterized Action Primitives},
Booktitle = {NeurIPS},
Year = {2021}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
dataset
Continual learning (CL) is widely regarded as crucial challenge for lifelong AI. However, existing CL benchmarks, e.g. Permuted-MNIST and Split-CIFAR, make use of artificial temporal variation and do not align with or generalize to the real-world. In this paper, we introduce CLEAR, the first continual image classification benchmark dataset with a natural temporal evolution of visual concepts in the real world that spans a decade (2004-2014). We build CLEAR from existing large-scale image collections (YFCC100M) through a novel and scalable low-cost approach to visio-linguistic dataset curation. Our pipeline makes use of pretrained vision-language models (e.g. CLIP) to interactively build labeled datasets, which are further validated with crowd-sourcing to remove errors and even inappropriate images (hidden in original YFCC100M). The major strength of CLEAR over prior CL benchmarks is the smooth temporal evolution of visual concepts with real-world imagery, including both high-quality labeled data along with abundant unlabeled samples per time period for continual semi-supervised learning. We find that a simple unsupervised pre-training step can already boost state-of-the-art CL algorithms that only utilize fully-supervised data. Our analysis also reveals that mainstream CL evaluation protocols that train and test on iid data artificially inflate performance of CL system. To address this, we propose novel "streaming" protocols for CL that always test on the (near) future. Interestingly, streaming protocols (a) can simplify dataset curation since today's testset can be repurposed for tomorrow's trainset and (b) can produce more generalizable models with more accurate estimates of performance since all labeled data from each time-period is used for both training and testing (unlike classic iid train-test splits).
@inproceedings{lin2021clear,
title={The CLEAR Benchmark:
Continual LEArning on Real-World Imagery},
author={Lin, Zhiqiu and Shi, Jia and
Pathak, Deepak and Ramanan, Deva},
booktitle={Thirty-fifth Conference on
Neural Information Processing Systems
Datasets and Benchmarks Track (Round 2)},
year={2021}
}
|

|
webpage |
pdf |
abstract |
bibtex |
code
Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. YCB object set) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these 'local rankings' could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
@inproceedings{dasari2021rb2,
title={RB2: Robotic Manipulation
Benchmarking with a Twist},
author={Dasari, Sudeep and
Wang, Jianren and Hong, Joyce and
Bahl, Shikhar and Lin, Yixin and
Wang, Austin S and Thankaraj, Abitha
and Chahal, Karanbir Singh and
Calli, Berk and Gupta, Saurabh
and others},
booktitle={Thirty-fifth Conference
on Neural Information Processing
Systems Datasets and Benchmarks
Track (Round 2)},
year={2021}
}
|
|
webpage |
pdf |
abstract |
bibtex |
talk video
Legged locomotion is commonly studied and expressed as a discrete set of gait patterns, like walk, trot, gallop, which are usually treated as given and pre-programmed in legged robots for efficient locomotion at different speeds. However, fixing a set of pre-programmed gaits limits the generality of locomotion. Recent animal motor studies show that these conventional gaits are only prevalent in ideal flat terrain conditions while real-world locomotion is unstructured and more like bouts of intermittent steps. What principles could lead to both structured and unstructured patterns across mammals and how to synthesize them in robots? In this work, we take an analysis-by-synthesis approach and learn to move by minimizing mechanical energy. We demonstrate that learning to minimize energy consumption is sufficient for the emergence of natural locomotion gaits at different speeds in real quadruped robots. The emergent gaits are structured in ideal terrains and look similar to that of horses and sheep. The same approach leads to unstructured gaits in rough terrains which is consistent with the findings in animal motor control. We validate our hypothesis in both simulation and real hardware across natural terrains.
@article{fu2021minimizing,
author = {Fu, Zipeng and
Kumar, Ashish and Malik, Jitendra
and Pathak, Deepak},
title = {Minimizing Energy
Consumption Leads to the Emergence
of Gaits in Legged Robots},
journal= {Conference on Robot Learning (CoRL)},
year = {2021}
}
|
|

|
webpage |
pdf |
abstract |
bibtex |
arXiv |
talk video
We tackle the problem of generalization to unseen configurations for dynamic tasks in the real world while learning from high-dimensional image input. The family of nonlinear dynamical system-based methods have successfully demonstrated dynamic robot behaviors but have difficulty in generalizing to unseen configurations as well as learning from image inputs. Recent works approach this issue by using deep network policies and reparameterize actions to embed the structure of dynamical systems but still struggle in domains with diverse configurations of image goals, and hence, find it difficult to generalize. In this paper, we address this dichotomy by leveraging embedding the structure of dynamical systems in a hierarchical deep policy learning framework, called Hierarchical Neural Dynamical Policies (H-NDPs). Instead of fitting deep dynamical systems to diverse data directly, H-NDPs form a curriculum by learning local dynamical system-based policies on small regions in state-space and then distill them into a global dynamical system-based policy that operates only from high-dimensional images. H-NDPs additionally provide smooth trajectories, a strong safety benefit in the real world. We perform extensive experiments on dynamic tasks both in the real world (digit writing, scooping, and pouring) and simulation (catching, throwing, picking). We show that H-NDPs are easily integrated with both imitation as well as reinforcement learning setups and achieve state-of-the-art results.
@article{bahl2021hndp,
author = {Bahl, Shikhar and
Gupta, Abhinav and Pathak, Deepak},
title = {Hierarchical Neural
Dynamic Policies},
journal= {RSS},
year = {2021}
}
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
talk video
Successful real-world deployment of legged robots would require them to adapt in real-time to unseen scenarios like changing terrains, changing payloads, wear and tear. This paper presents Rapid Motor Adaptation (RMA) algorithm to solve this problem of real-time online adaptation in quadruped robots. RMA consists of two components: a base policy and an adaptation module. The combination of these components enables the robot to adapt to novel situations in fractions of a second. RMA is trained completely in simulation without using any domain knowledge like reference trajectories or predefined foot trajectory generators and is deployed on the A1 robot without any fine-tuning. We train RMA on a varied terrain generator using bioenergetics-inspired rewards and deploy it on a variety of difficult terrains including rocky, slippery, deformable surfaces in environments with grass, long vegetation, concrete, pebbles, stairs, sand, etc. RMA shows state-of-the-art performance across diverse real-world as well as simulation experiments.
@article{kumar2021rma,
author = {Kumar, Ashish and
Fu, Zipeng and Pathak, Deepak
and Malik, Jitendra},
title = {RMA: Rapid Motor
Adaptation for Legged Robots},
journal= {RSS},
year = {2021}
}
|
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
demo video
We present Worldsheet, a method for novel view synthesis using just a single RGB image as input. This is a challenging problem as it requires an understanding of the 3D geometry of the scene as well as texture mapping to generate both visible and occluded regions from new view-points. Our main insight is that simply shrink-wrapping a planar mesh sheet onto the input image, consistent with the learned intermediate depth, captures underlying geometry sufficient enough to generate photorealistic unseen views with arbitrarily large view-point changes. To operationalize this, we propose a novel differentiable texture sampler that allows our wrapped mesh sheet to be textured; which is then transformed into a target image via differentiable rendering. Our approach is category-agnostic, end-to-end trainable without using any 3D supervision and requires a single image at test time. Worldsheet consistently outperforms prior state-of-the-art methods on single-image view synthesis across several datasets. Furthermore, this simple idea captures novel views surprisingly well on a wide range of high resolution in-the-wild images in converting them into a navigable 3D pop-up.
@article{hu2020worldsheet,
author = {Hu, Ronghang and
Ravi, Nikhila and Berg, Alex
and Pathak, Deepak},
title = {Worldsheet: Wrapping
the World in a 3D Sheet for View
Synthesis from a Single Image},
journal= {ICCV},
year = {2020}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
talk video
Learning sensorimotor control policies from high-dimensional images crucially relies on the quality of the underlying visual representations. Prior works show that structured latent space such as visual keypoints often outperforms unstructured representations for robotic control. However, most of these representations, whether structured or unstructured are learned in a 2D space even though the control tasks are usually performed in a 3D environment. In this work, we propose a framework to learn such a 3D geometric structure directly from images in an end-to-end unsupervised manner. The input images are embedded into latent 3D keypoints via a differentiable encoder which is trained to optimize both a multi-view consistency loss and downstream task objective. These discovered 3D keypoints tend to meaningfully capture robot joints as well as object movements in a consistent manner across both time and 3D space. The proposed approach outperforms prior state-of-art methods across a variety of reinforcement learning benchmarks.
@article{chen2021keypoint3D,
author = {Chen, Boyuan and
Abbeel, Pieter and Pathak, Deepak},
title = {Unsupervised Learning
of Visual 3D Keypoints for
Control},
journal= {ICML},
year = {2021}
}
|
 |
webpage |
pdf |
abstract |
bibtex
talk video
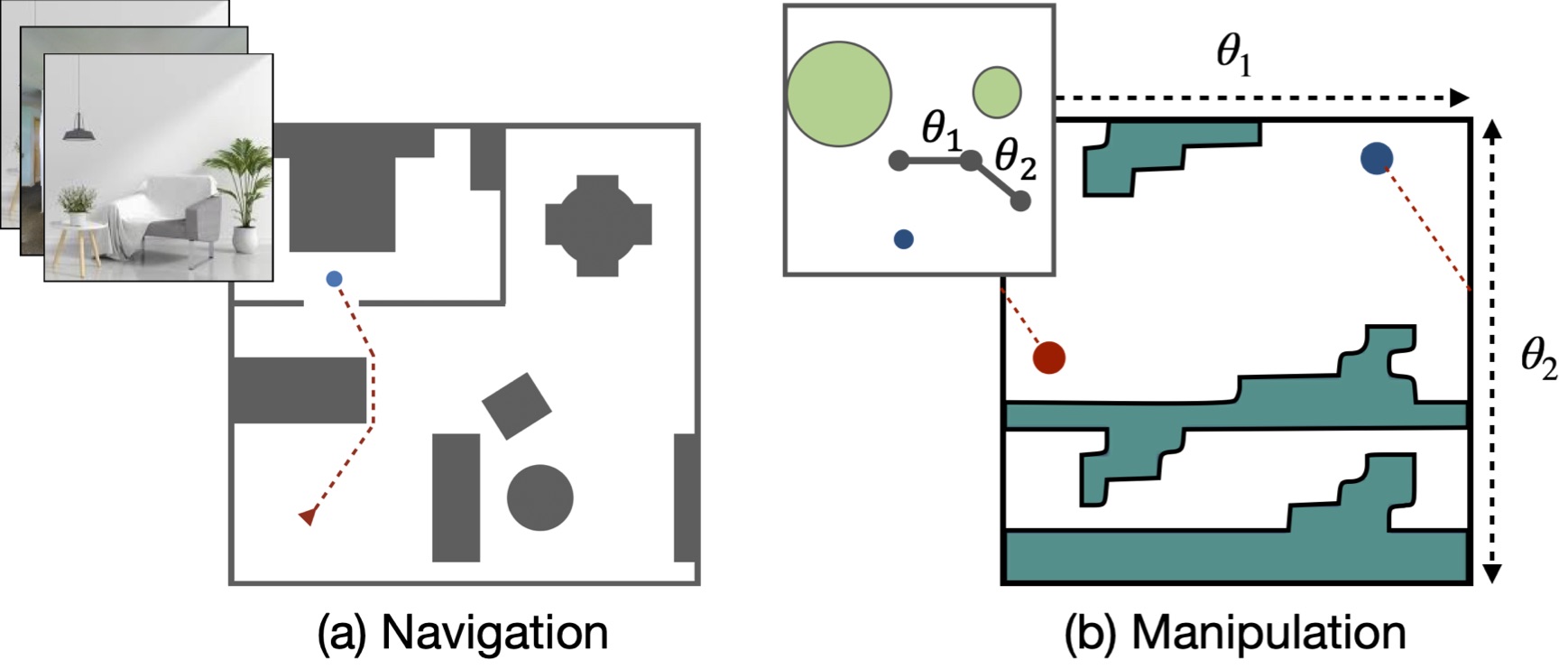
We consider the problem of spatial path planning. In contrast to the classical solutions which optimize a new plan from scratch and assume access to the full map with ground truth obstacle locations, we learn a planner from the data in a differentiable manner that allows us to leverage statistical regularities from past data. We propose Spatial Planning Transformers (SPT), which given an obstacle map learns to generate actions by planning over long-range spatial dependencies, unlike prior data-driven planners that propagate information locally via convolutional structure in an iterative manner. In the setting where the ground truth map is not known to the agent, we leverage pre-trained SPTs in an end-to-end framework that has the structure of mapper and planner built into it which allows seamless generalization to out-of-distribution maps and goals. SPTs outperform prior state-of-the-art differentiable planners across all the setups for both manipulation and navigation tasks, leading to an absolute improvement of 7-19%.
@article{chaplot21spt,
author = {Chaplot, Devendra Singh and
Pathak, Deepak and Malik, Jitendra},
title = {Differentiable Spatial
Planning using Transformers},
journal= {ICML},
year = {2021}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
code |
demo video
Policies trained in simulation often fail when transferred to the real world due to the 'reality gap' where the simulator is unable to sufficiently accurately capture the dynamics and visual properties of the real world. Current approaches to tackle this problem, such as domain randomization, require prior knowledge and engineering to determine how much to randomize system parameters in order to learn a policy that is robust to sim-to-real transfer while also not being too conservative. We propose a method for automatically tuning system parameters of simulator to match the real world using only raw observation images without the need to define rewards or estimate state in the real world itself. Our key insight is to reframe the auto-tuning of parameters as a search problem where we iteratively shift the simulation system parameters to approach the real world system parameters. We propose a Search Param Model (SPM) that, given a sequence of observations and actions and a set of system parameters, predicts whether the parameters are higher or lower than the true parameters used to generate the observations. We evaluate our method on multiple robotic control tasks in both sim-to-sim and sim-to-real transfer, demonstrating significant improvement over the conventional approach of domain randomization.
@article{du2021autotuned,
author = {Du, Yuqing and
Watkins, Olivia and
Darrell, Trevor and Abbeel, Pieter
and Pathak, Deepak},
title = {Auto-Tuned Sim-to-Real
Transfer},
journal= {ICRA},
year = {2021}
}
|
 |
pdf |
abstract |
bibtex
Hierarchical learning has been successful at learning generalizable locomotion skills on walking robots in a sample-efficient manner. However, the low-dimensional "latent" action used to communicate between two layers of the hierarchy is typically user-designed. In this work, we present a fully-learned hierarchical framework, that is capable of jointly learning the low-level controller and the high-level latent action space. Once this latent space is learned, we plan over continuous latent actions in a model-predictive control fashion, using a learned high-level dynamics model. This framework generalizes to multiple robots, and we present results on a Daisy hexapod simulation, A1 quadruped simulation, and Daisy robot hardware. We compare a range of learned hierarchical approaches from literature, and show that our framework outperforms baselines on multiple tasks and two simulations. In addition to learning approaches, we also compare to inverse-kinematics (IK) acting on desired robot motion, and show that our fully-learned framework outperforms IK in adverse settings on both A1 and Daisy simulations. On hardware, we show the Daisy hexapod achieve multiple locomotion tasks, in an unstructured outdoor setting, with only 2000 hardware samples, reinforcing the robustness and sample-efficiency of our approach.
@article{li2021planning,
title={Planning in learned latent
action spaces for generalizable
legged locomotion},
author={Li, Tianyu and
Calandra, Roberto and Pathak, Deepak
and Tian, Yuandong and
Meier, Franziska and Rai, Akshara},
journal={IEEE Robotics and
Automation Letters},
year={2021}
}
|
 Ours GT |
webpage |
pdf |
abstract |
bibtex |
code
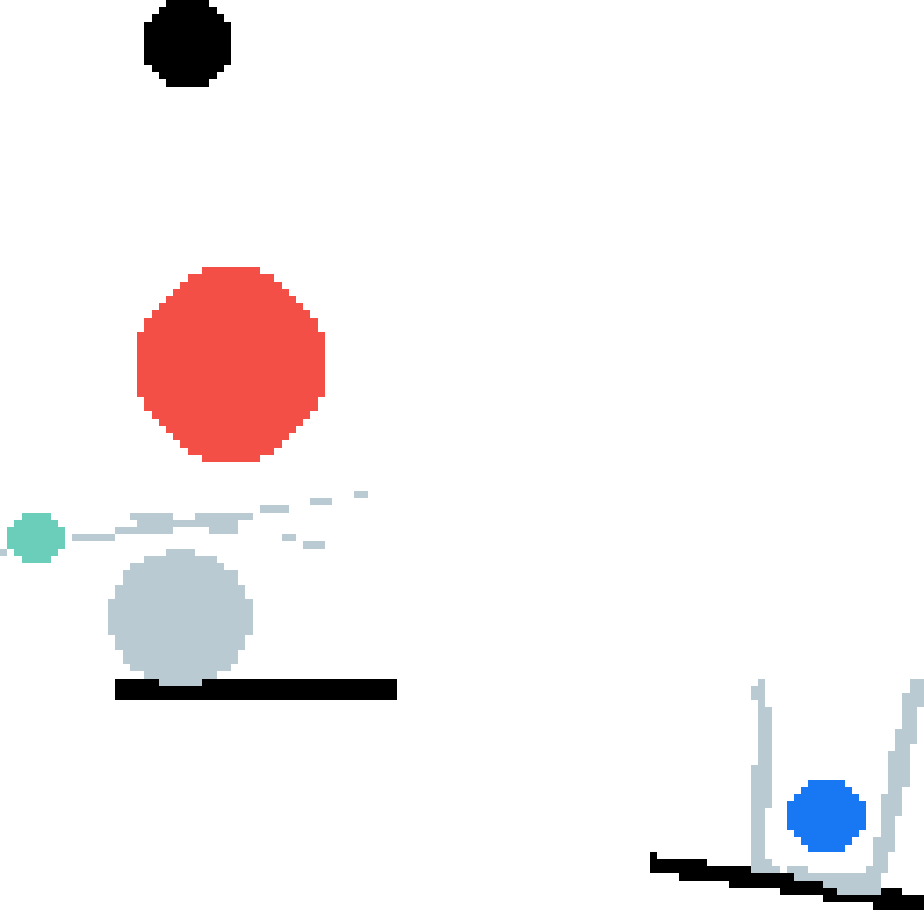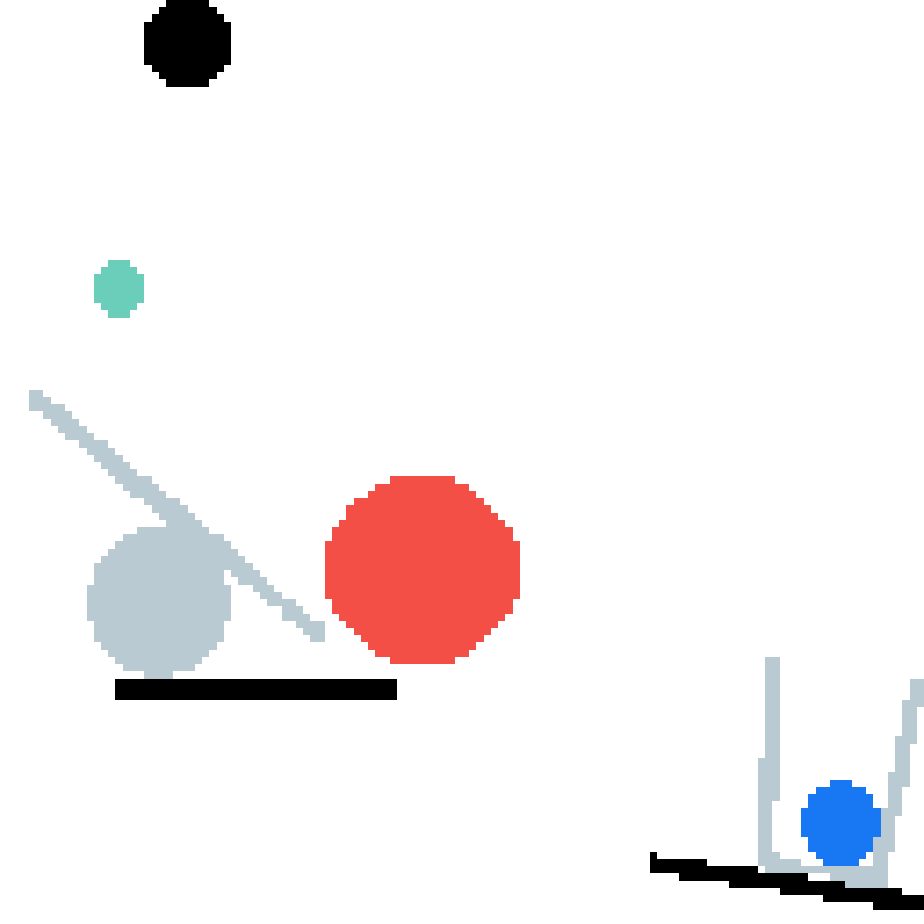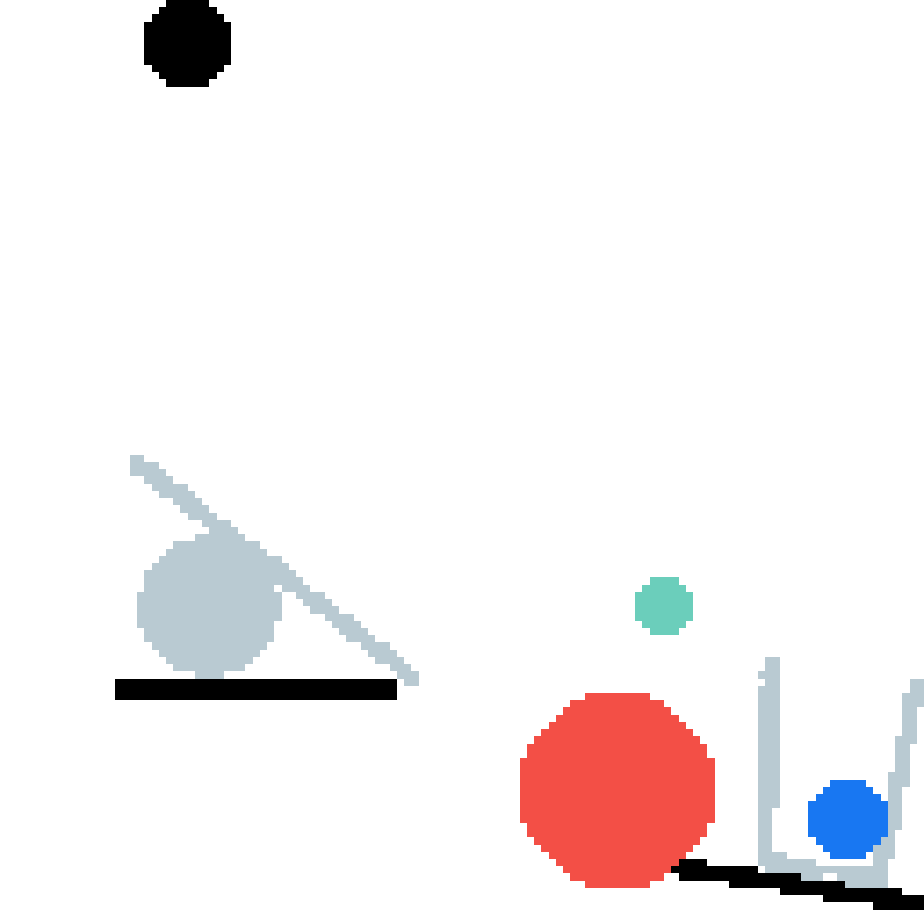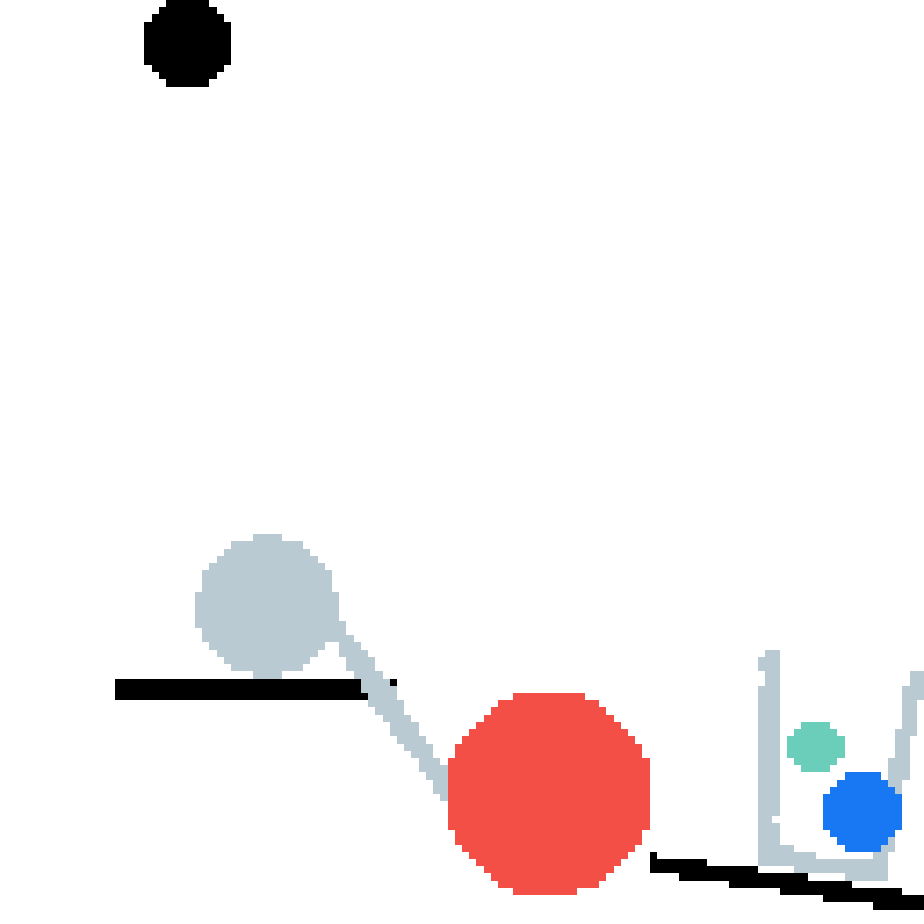
Learning long-term dynamics models is the key to understanding physical common sense. Most existing approaches on learning dynamics from visual input sidestep long-term predictions by resorting to rapid re-planning with short-term models. This not only requires such models to be super accurate but also limits them only to tasks where an agent can continuously obtain feedback and take action at each step until completion. In this paper, we aim to leverage the ideas from success stories in visual recognition tasks to build object representations that can capture inter-object and object-environment interactions over a long-range. To this end, we propose Region Proposal Interaction Networks (RPIN), which reason about each object's trajectory in a latent region-proposal feature space. Thanks to the simple yet effective object representation, our approach outperforms prior methods by a significant margin both in terms of prediction quality and their ability to plan for downstream tasks, and also generalize well to novel environments.
@inproceedings{qiICLR21,
Author = {Qi, Haozhi and
Wang, Xiaolong and Pathak, Deepak
and Ma, Yi and Malik, Jitendra},
Title = {Learning Long-term Visual
Dynamics with Region Proposal
Interaction Networks},
Booktitle = {ICLR},
Year = {2021}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
demo |
spotlight talk
The current dominant paradigm in sensorimotor control, whether imitation or reinforcement learning, is to train policies directly in raw action spaces such as torque, joint angle, or end-effector position. This forces the agent to make decision at each point in training, and hence, limit the scalability to continuous, high-dimensional, and long-horizon tasks. In contrast, research in classical robotics has, for a long time, exploited dynamical systems as a policy representation to learn robot behaviors via demonstrations. These techniques, however, lack the flexibility and generalizability provided by deep learning or deep reinforcement learning and have remained under-explored in such settings. In this work, we begin to close this gap and embed dynamics structure into deep neural network-based policies by reparameterizing action spaces with differential equations. We propose Neural Dynamic Policies (NDPs) that make predictions in trajectory distribution space as opposed to prior policy learning methods where action represents the raw control space. The embedded structure allow us to perform end-to-end policy learning under both reinforcement and imitation learning setups. We show that NDPs achieve better or comparable performance to state-of-the-art approaches on many robotic control tasks using both reward-based training and demonstrations.
@inproceedings{bahl2020ndp,
Author = {Bahl, Shikhar and
Mukadam, Mustafa and
Gupta, Abhinav and Pathak, Deepak},
Title = {Neural Dynamic Policies
for End-to-End Sensorimotor Learning},
Booktitle = {NeurIPS},
Year = {2020}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
video |
code
To operate effectively in the real world, agents should be able to act from high-dimensional raw sensory input such as images and achieve diverse goals across long time-horizons. Current deep reinforcement and imitation learning methods can learn directly from high-dimensional inputs but do not scale well to long-horizon tasks. In contrast, classical graphical methods like A* search are able to solve long-horizon tasks, but assume that the state space is abstracted away from raw sensory input. Recent works have attempted to combine the strengths of deep learning and classical planning; however, dominant methods in this domain are still quite brittle and scale poorly with the size of the environment. We introduce Sparse Graphical Memory (SGM), a new data structure that stores states and feasible transitions in a sparse memory. SGM aggregates states according to a novel two-way consistency objective, adapting classic state aggregation criteria to goal-conditioned RL: two states are redundant when they are interchangeable both as goals and as starting states. Theoretically, we prove that merging nodes according to two-way consistency leads to an increase in shortest path lengths that scales only linearly with the merging threshold. Experimentally, we show that SGM significantly outperforms current state of the art methods on long horizon, sparse-reward visual navigation tasks.
@inproceedings{laskin2020sparse,
Author = {Emmons, Scott and Jain, Ajay
and Laskin, Michael and Kurutach, Thanard
and Abbeel, Pieter and Pathak, Deepak},
Title = {Sparse Graphical
Memory for Robust Planning},
Booktitle = {NeurIPS},
Year = {2020}
}
|
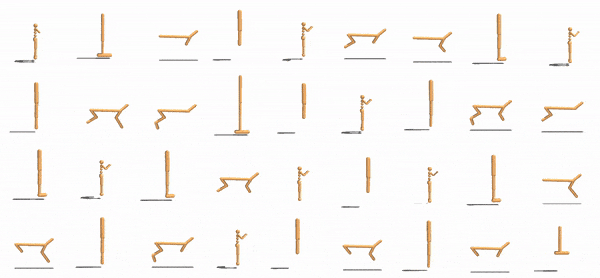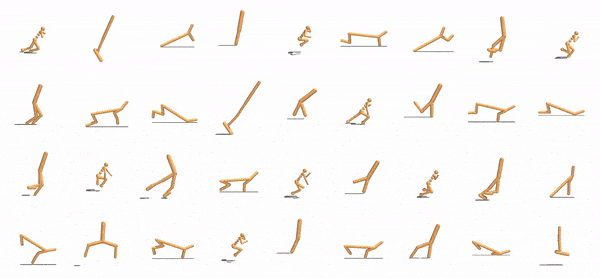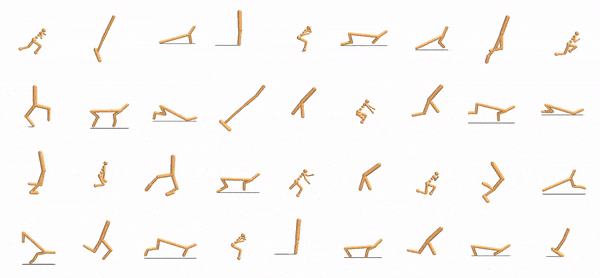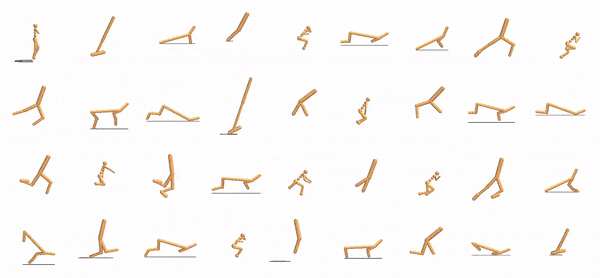 |
webpage |
pdf |
abstract |
bibtex |
code |
demo video |
oral talk
Reinforcement learning is typically concerned with learning control policies tailored to a particular agent. We investigate whether there exists a single global policy that can generalize to control a wide variety of agent morphologies -- ones in which even dimensionality of state and action spaces changes. We propose to express this global policy as a collection of identical modular neural networks, dubbed as Shared Modular Policies (SMP), that correspond to each of the agent's actuators. Every module is only responsible for controlling its corresponding actuator and receives information from only its local sensors. In addition, messages are passed between modules, propagating information between distant modules. We show that a single modular policy can successfully generate locomotion behaviors for several planar agents with different skeletal structures such as monopod hoppers, quadrupeds, bipeds, and generalize to variants not seen during training -- a process that would normally require training and manual hyperparameter tuning for each morphology. We observe that a wide variety of drastically diverse locomotion styles across morphologies as well as centralized coordination emerges via message passing between decentralized modules purely from the reinforcement learning objective.
@inproceedings{huang2020smp,
Author = {Huang, Wenlong and
Mordatch, Igor and Pathak, Deepak},
Title = {One Policy to Control
Them All: Shared Modular Policies
for Agent-Agnostic Control},
Booktitle = {ICML},
Year = {2020}
}
|
 |
webpage |
abstract |
bibtex |
code |
video |
oral talk |
in the media
Reinforcement learning allows solving complex tasks, however, the learning tends to be task-specific and the sample efficiency remains a challenge. We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner. We evaluate on challenging control tasks from high-dimensional image inputs. Without any training supervision or task-specific interaction, Plan2Explore outperforms prior self-supervised exploration methods, and in fact, almost matches the performances oracle which has access to rewards.
@inproceedings{sekar2020planning,
Author = {Sekar, Ramanan and Rybkin, Oleh
and Daniilidis, Kostas and Abbeel, Pieter
and Hafner, Danijar and Pathak, Deepak},
Title = {Planning to Explore
via Self-Supervised World Models},
Booktitle = {ICML},
Year = {2020}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
code
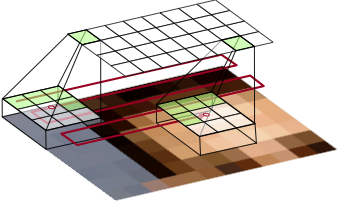
High-dimensional generative models have many applications including image compression, multimedia generation, anomaly detection and data completion. State-of-the-art estimators for natural images are autoregressive, decomposing the joint distribution over pixels into a product of conditionals parameterized by a deep neural network, e.g. a convolutional neural network such as the PixelCNN. However, PixelCNNs only model a single decomposition of the joint, and only a single generation order is efficient. For tasks such as image completion, these models are unable to use much of the observed context. To generate data in arbitrary orders, we introduce LMConv: a simple modification to the standard 2D convolution that allows arbitrary masks to be applied to the weights at each location in the image. Using LMConv, we learn an ensemble of distribution estimators that share parameters but differ in generation order, achieving improved performance on whole-image density estimation (2.89 bpd on unconditional CIFAR10), as well as globally coherent image completions.
@inproceedings{jain2020uai,
Author = {Jain, Ajay and
Abbeel, Pieter and Pathak, Deepak},
Title = {Locally Masked Convolution
for Autoregressive Models},
Booktitle = {UAI},
Year = {2020}
}
|
 |
pdf |
abstract |
bibtex
Generative Adversarial Networks (GANs) can produce images of surprising complexity and realism, but are generally modeled to sample from a single latent source ignoring the explicit spatial interaction between multiple entities that could be present in a scene. Capturing such complex interactions between different objects in the world, including their relative scaling, spatial layout, occlusion, or viewpoint transformation is a challenging problem. In this work, we propose to model object composition in a GAN framework as a self-consistent composition-decomposition network. Our model is conditioned on the object images from their marginal distributions to generate a realistic image from their joint distribution by explicitly learning the possible interactions. We evaluate our model through qualitative experiments and user evaluations in both the scenarios when either paired or unpaired examples for the individual object images and the joint scenes are given during training. Our results reveal that the learned model captures potential interactions between the two object domains given as input to output new instances of composed scene at test time in a reasonable fashion.
@inproceedings{azadi18compgan,
Author = {Azadi, Samaneh and
Pathak, Deepak and
Ebrahimi, Sayna and Darrell, Trevor},
Title = {Compositional GAN: Learning
Conditional Image Composition},
Booktitle = {IJCV},
Year = {2020}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
video |
code
Contemporary sensorimotor learning approaches typically start with an existing complex agent (e.g., a robotic arm), which they learn to control. In contrast, this paper investigates a modular co-evolution strategy: a collection of primitive agents learns to dynamically self-assemble into composite bodies while also learning to coordinate their behavior to control these bodies. Each primitive agent consists of a limb with a motor attached at one end. Limbs may choose to link up to form collectives. When a limb initiates a link-up action and there is another limb nearby, the latter is magnetically connected to the 'parent' limb's motor. This forms a new single agent, which may further link with other agents. In this way, complex morphologies can emerge, controlled by a policy whose architecture is in explicit correspondence with the morphology. We evaluate the performance of these dynamic and modular agents in simulated environments. We demonstrate better generalization to test-time changes both in the environment, as well as in the agent morphology, compared to static and monolithic baselines.
@inproceedings{pathak19assemblies,
Author = {Pathak, Deepak and
Lu, Chris and Darrell, Trevor and
Isola, Phillip and Efros, Alexei A.},
Title = {Learning to Control Self-
Assembling Morphologies: A Study of
Generalization via Modularity},
Booktitle = {NeurIPS},
Year = {2019}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
video |
code
We study a generalized setup for learning from demonstration to build an agent that can manipulate novel objects in unseen scenarios by looking at only a single video of human demonstration from a third-person perspective. To accomplish this goal, our agent should not only learn to understand the intent of the demonstrated third-person video in its context but also perform the intended task in its environment configuration. Our central insight is to enforce this structure explicitly during learning by decoupling what to achieve (intended task) from how to perform it (controller). We propose a hierarchical setup where a high-level module learns to generate a series of first-person sub-goals conditioned on the third-person video demonstration, and a low-level controller predicts the actions to achieve those sub-goals. Our agent acts from raw image observations without any access to the full state information. We show results on a real robotic platform using Baxter for the manipulation tasks of pouring and placing objects in a box.
@inproceedings{sharma19thirdperson,
Author = {Sharma, Pratyusha and
Pathak, Deepak and Gupta, Abhinav},
Title = {Third-Person Visual Imitation Learning
via Decoupled Hierarchical Controller},
Booktitle = {NeurIPS},
Year = {2019}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
video |
oral talk
Efficient exploration is a long-standing problem in sensorimotor learning. Major advances have been demonstrated in noise-free, non-stochastic domains such as video games and simulation. However, most of these formulations either get stuck in environments with stochastic dynamics or are too inefficient to be scalable to real robotics setups. In this paper, we propose a formulation for exploration inspired by the work in active learning literature. Specifically, we train an ensemble of dynamics models and incentivize the agent to explore such that the disagreement of those ensembles is maximized. This allows the agent to learn skills by exploring in a self-supervised manner without any external reward. Notably, we further leverage the disagreement objective to optimize the agent's policy in a differentiable manner, without using reinforcement learning, which results in a sample-efficient exploration. We demonstrate the efficacy of this formulation across a variety of benchmark environments including stochastic-Atari, Mujoco and Unity. Finally, we implement our differentiable exploration on a real robot which learns to interact with objects completely from scratch.
@inproceedings{pathak19disagreement,
Author = {Pathak, Deepak and
Gandhi, Dhiraj and Gupta, Abhinav},
Title = {Self-Supervised Exploration
via Disagreement},
Booktitle = {ICML},
Year = {2019}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
video |
code |
in the media
Also presented at NIPS'18 Deep RL Workshop (Oral Presentation) Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups.
@inproceedings{pathakICLR19largescale,
Author = {Burda, Yuri and
Edwards, Harri and Pathak, Deepak and
Storkey, Amos and Darrell, Trevor and
Efros, Alexei A.},
Title = {Large-Scale Study of
Curiosity-Driven Learning},
Booktitle = {ICLR},
Year = {2019}
}
|
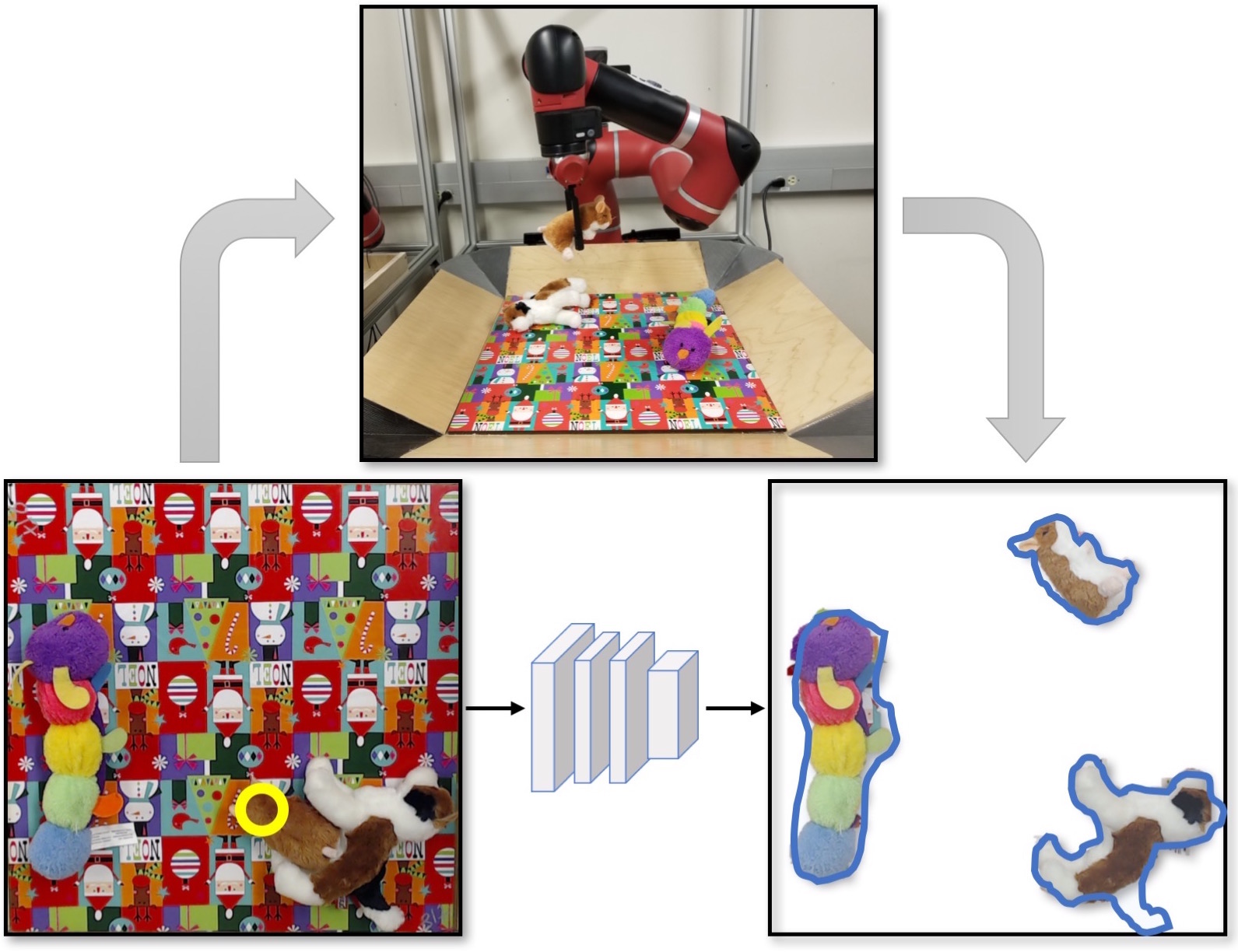 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
We present an approach for building an active agent that learns to segment its visual observations into individual objects by interacting with its environment in a completely self-supervised manner. The agent uses its current segmentation model to infer pixels that constitute objects and refines the segmentation model by interacting with these pixels. The model learned from over 50K interactions generalizes to novel objects and backgrounds. To deal with noisy training signal for segmenting objects obtained by self-supervised interactions, we propose robust set loss. A dataset of robot's interactions along-with a few human labeled examples is provided as a benchmark for future research. We test the utility of the learned segmentation model by providing results on a downstream vision-based control task of rearranging multiple objects into target configurations from visual inputs alone.
@inproceedings{pathakCVPRW18segByInt,
Author = {Pathak, Deepak and
Shentu, Yide and Chen, Dian and
Agrawal, Pulkit and Darrell, Trevor and
Levine, Sergey and Malik, Jitendra},
Title = {Learning Instance Segmentation
by Interaction},
Booktitle = {CVPR Workshop on Benchmarks for
Deep Learning in Robotic Vision},
Year = {2018}
}
|
  |
webpage |
abstract |
bibtex |
code |
videos |
open-review |
slides
The current dominant paradigm for imitation learning relies on strong supervision of expert actions to learn both 'what' and 'how' to imitate. We pursue an alternative paradigm wherein an agent first explores the world without any expert supervision and then distills its experience into a goal-conditioned skill policy with a novel forward consistency loss. In our framework, the role of the expert is only to communicate the goals (i.e., what to imitate) during inference. The learned policy is then employed to mimic the expert (i.e., how to imitate) after seeing just a sequence of images demonstrating the desired task. Our method is 'zero-shot' in the sense that the agent never has access to expert actions during training or for the task demonstration at inference. We evaluate our zero-shot imitator in two real-world settings: complex rope manipulation with a Baxter robot and navigation in previously unseen office environments with a TurtleBot. Through further experiments in VizDoom simulation, we provide evidence that better mechanisms for exploration lead to learning a more capable policy which in turn improves end task performance.
@inproceedings{pathakICLR18zeroshot,
Author = {Pathak, Deepak and
Mahmoudieh, Parsa and Luo, Guanghao and
Agrawal, Pulkit and Chen, Dian and
Shentu, Yide and Shelhamer, Evan and
Malik, Jitendra and Efros, Alexei A. and
Darrell, Trevor},
Title = {Zero-Shot Visual Imitation},
Booktitle = {ICLR},
Year = {2018}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
video |
in the media
Also presented at ICLR'18 Workshop track. What makes humans so good at solving seemingly complex video games? Unlike computers, humans bring in a great deal of prior knowledge about the world, enabling efficient decision making. This paper investigates the role of human priors for solving video games. Given a sample game, we conduct a series of ablation studies to quantify the importance of various priors on human performance. We do this by modifying the video game environment to systematically mask different types of visual information that could be used by humans as priors. We find that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Furthermore, our results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play.
@inproceedings{pathakICML18human,
Author = {Dubey, Rachit and Agrawal, Pulkit
and Pathak, Deepak and Griffiths, Thomas L.
and Efros, Alexei A.},
Title = {Investigating Human Priors for
Playing Video Games},
Booktitle = {ICML},
Year = {2018}
}
|
  |
webpage |
pdf |
abstract |
bibtex |
code |
video |
oral |
in the media
Also presented at CVPR'17 Robotic Vision Workshop (Oral Presentation) In many real-world scenarios, rewards extrinsic to the agent are extremely sparse, or absent altogether. In such cases, curiosity can serve as an intrinsic reward signal to enable the agent to explore its environment and learn skills that might be useful later in its life. We formulate curiosity as the error in an agent's ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model. Our formulation scales to high-dimensional continuous state spaces like images, bypasses the difficulties of directly predicting pixels, and, critically, ignores the aspects of the environment that cannot affect the agent. The proposed approach is evaluated in two environments: VizDoom and Super Mario Bros. Three broad settings are investigated: 1) sparse extrinsic reward, where curiosity allows for far fewer interactions with the environment to reach the goal; 2) exploration with no extrinsic reward, where curiosity pushes the agent to explore more efficiently; and 3) generalization to unseen scenarios (e.g. new levels of the same game) where the knowledge gained from earlier experience helps the agent explore new places much faster than starting from scratch.
@inproceedings{pathakICMl17curiosity,
Author = {Pathak, Deepak and
Agrawal, Pulkit and
Efros, Alexei A. and
Darrell, Trevor},
Title = {Curiosity-driven Exploration
by Self-supervised Prediction},
Booktitle = {ICML},
Year = {2017}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
video
Many image-to-image translation problems are ambiguous, as a single input image may correspond to multiple possible outputs. In this work, we aim to model a distribution of possible outputs in a conditional generative modeling setting. The ambiguity of the mapping is distilled in a low-dimensional latent vector, which can be randomly sampled at test time. A generator learns to map the given input, combined with this latent code, to the output. We explicitly encourage the connection between output and the latent code to be invertible. This helps prevent a many-to-one mapping from the latent code to the output during training, also known as the problem of mode collapse, and produces more diverse results. We explore several variants of this approach by employing different training objectives, network architectures, and methods of injecting the latent code. Our proposed method encourages bijective consistency between the latent encoding and output modes. We present a systematic comparison of our method and other variants on both perceptual realism and diversity.
@inproceedings{zhu2017multimodal,
Author = {Zhu, Jun-Yan and Zhang, Richard
and Pathak, Deepak and Darrell, Trevor
and Efros, Alexei A and Wang, Oliver
and Shechtman, Eli},
Title = {Toward Multimodal Image-to-Image
Translation},
Booktitle = {NIPS},
Year = {2017}
}
|
 |
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Also presented at YouTube-8M Video Understanding Workshop (Oral Presentation) This paper presents a novel yet intuitive approach to unsupervised feature learning. Inspired by the human visual system, we explore whether low-level motion-based grouping cues can be used to learn an effective visual representation. Specifically, we use unsupervised motion-based segmentation on videos to obtain segments, which we use as `pseudo ground truth' to train a convolutional network to segment objects from a single frame. Given the extensive evidence that motion plays a key role in the development of the human visual system, we hope that this straightforward approach to unsupervised learning will be more effective than cleverly designed `pretext' tasks studied in the literature. Indeed, our extensive experiments show that this is the case. When used for transfer learning on object detection, our representation significantly outperforms previous unsupervised approaches across multiple settings, especially when training data for the target task is scarce.
@inproceedings{pathakCVPR17learning,
Author = {Pathak, Deepak and
Girshick, Ross and
Doll{\'a}r, Piotr and
Darrell, Trevor and
Hariharan, Bharath},
Title = {Learning Features
by Watching Objects Move},
Booktitle = {CVPR},
Year = {2017}
}
|
 |
webpage |
pdf w/ supp |
abstract |
bibtex |
arXiv |
code |
slides
We present an unsupervised visual feature learning algorithm driven by context-based pixel prediction. By analogy with auto-encoders, we propose Context Encoders -- a convolutional neural network trained to generate the contents of an arbitrary image region conditioned on its surroundings. In order to succeed at this task, context encoders need to both understand the content of the entire image, as well as produce a plausible hypothesis for the missing part(s). When training context encoders, we have experimented with both a standard pixel-wise reconstruction loss, as well as a reconstruction plus an adversarial loss. The latter produces much sharper results because it can better handle multiple modes in the output. We found that a context encoder learns a representation that captures not just appearance but also the semantics of visual structures. We quantitatively demonstrate the effectiveness of our learned features for CNN pre-training on classification, detection, and segmentation tasks. Furthermore, context encoders can be used for semantic inpainting tasks, either stand-alone or as initialization for non-parametric methods.
@inproceedings{pathakCVPR16context,
Author = {Pathak, Deepak and
Kr\"ahenb\"uhl, Philipp and
Donahue, Jeff and
Darrell, Trevor and
Efros, Alexei A.},
Title = {Context Encoders:
Feature Learning by Inpainting},
Booktitle = {CVPR},
Year = {2016}
}
|
 |
pdf |
abstract |
bibtex |
jmlr
A major barrier towards scaling visual recognition systems is the difficulty of obtaining labeled images for large numbers of categories. Recently, deep convolutional neural networks (CNNs) trained used 1.2M+ labeled images have emerged as clear winners on object classification benchmarks. Unfortunately, only a small fraction of those labels are available with bounding box localization for training the detection task and even fewer pixel level annotations are available for semantic segmentation. It is much cheaper and easier to collect large quantities of image-level labels from search engines than it is to collect scene-centric images with precisely localized labels. We develop methods for learning large scale recognition models which exploit joint training over both weak (image-level) and strong (bounding box) labels and which transfer learned perceptual representations from strongly-labeled auxiliary tasks. We provide a novel formulation of a joint multiple instance learning method that includes examples from object-centric data with image-level labels when available, and also performs domain transfer learning to improve the underlying detector representation. We then show how to use our large scale detectors to produce pixel level annotations. Using our method, we produce a >7.6K category detector and release code and models at lsda.berkeleyvision.org.
@inproceedings{pathakJMLR16,
Author = {Hoffman, Judy and
Pathak, Deepak and
Tzeng, Eric and
Long, Jonathan and
Guadarrama, Sergio and
Darrell, Trevor and
Saenko, Kate},
Title = {Large Scale Visual Recognition
through Adaptation using Joint
Representation and Multiple Instance
Learning},
Booktitle = {JMLR},
Year = {2016}
}
|
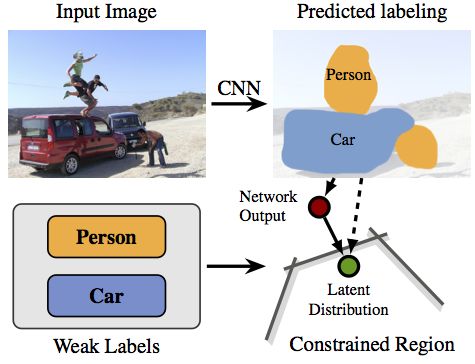 |
pdf |
supp |
abstract |
bibtex |
arXiv |
code
We present an approach to learn a dense pixel-wise labeling from image-level tags. Each image-level tag imposes constraints on the output labeling of a Convolutional Neural Network (CNN) classifier. We propose Constrained CNN (CCNN), a method which uses a novel loss function to optimize for any set of linear constraints on the output space (i.e. predicted label distribution) of a CNN. Our loss formulation is easy to optimize and can be incorporated directly into standard stochastic gradient descent optimization. The key idea is to phrase the training objective as a biconvex optimization for linear models, which we then relax to nonlinear deep networks. Extensive experiments demonstrate the generality of our new learning framework. The constrained loss yields state-of-the-art results on weakly supervised semantic image segmentation. We further demonstrate that adding slightly more supervision can greatly improve the performance of the learning algorithm.
@inproceedings{pathakICCV15ccnn,
Author = {Pathak, Deepak and
Kr\"ahenb\"uhl, Philipp and
Darrell, Trevor},
Title = {Constrained Convolutional
Neural Networks for Weakly
Supervised Segmentation},
Booktitle = {ICCV},
Year = {2015}
}
|
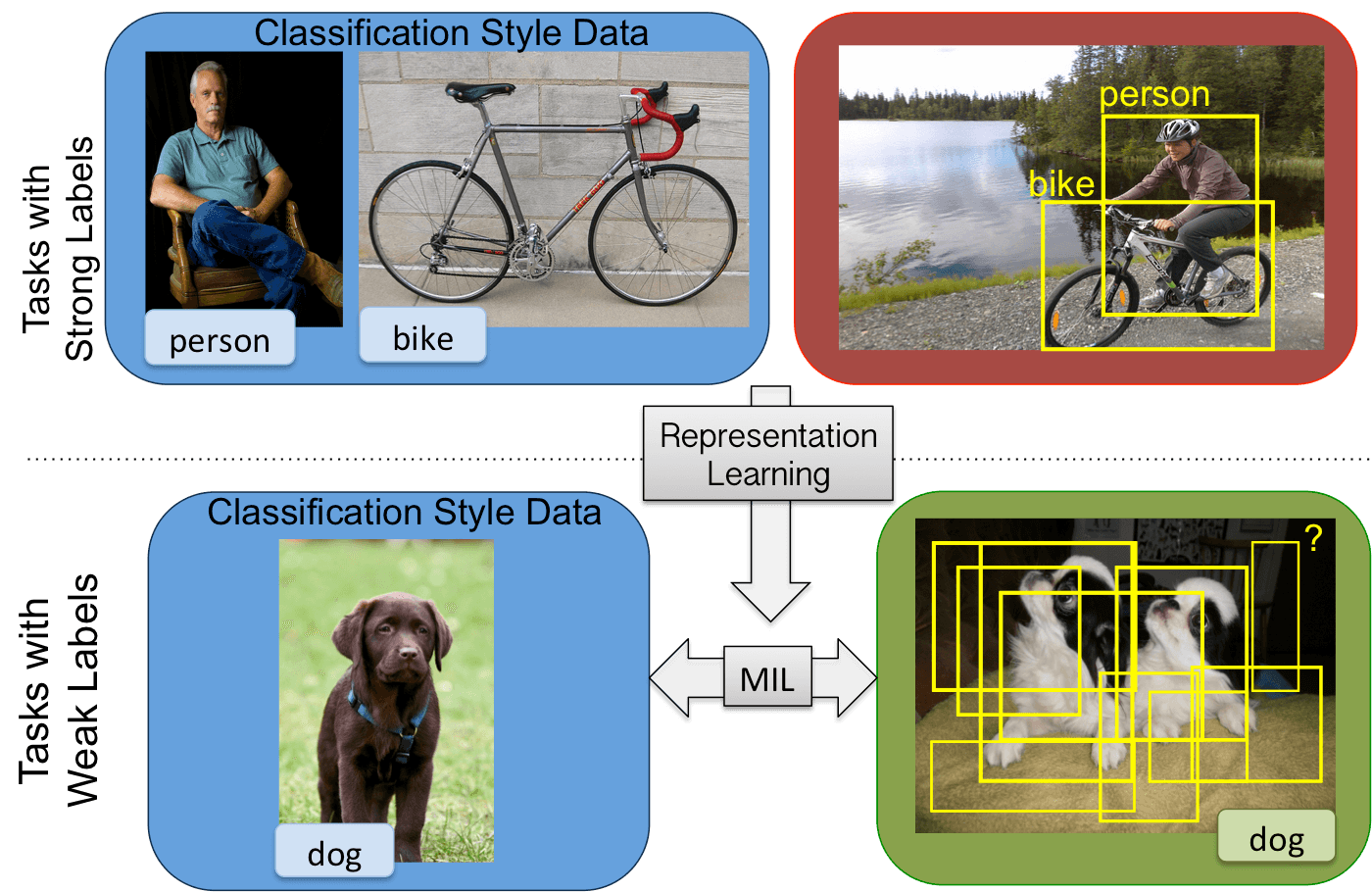 |
pdf |
abstract |
bibtex |
arXiv
We develop methods for detector learning which exploit joint training over both weak (image-level) and strong (bounding box) labels and which transfer learned perceptual representations from strongly-labeled auxiliary tasks. Previous methods for weak-label learning often learn detector models independently using latent variable optimization, but fail to share deep representation knowledge across classes and usually require strong initialization. Other previous methods transfer deep representations from domains with strong labels to those with only weak labels, but do not optimize over individual latent boxes, and thus may miss specific salient structures for a particular category. We propose a model that subsumes these previous approaches, and simultaneously trains a representation and detectors for categories with either weak or strong labels present. We provide a novel formulation of a joint multiple instance learning method that includes examples from classification-style data when available, and also performs domain transfer learning to improve the underlying detector representation. Our model outperforms known methods on ImageNet-200 detection with weak labels.
@inproceedings{pathakCVPR15,
Author = {Hoffman, Judy and
Pathak, Deepak and
Darrell, Trevor and
Saenko, Kate},
Title = {Detector Discovery
in the Wild: Joint Multiple
Instance and Representation
Learning},
Booktitle = {CVPR},
Year = {2015}
}
|
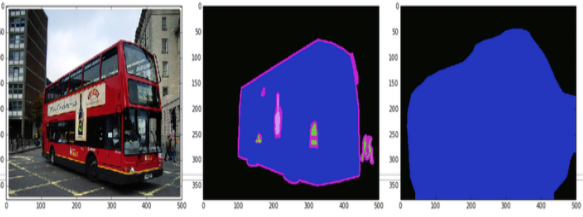 |
pdf |
abstract |
bibtex |
arXiv
Multiple instance learning (MIL) can reduce the need for costly annotation in tasks such as semantic segmentation by weakening the required degree of supervision. We propose a novel MIL formulation of multi-class semantic segmentation learning by a fully convolutional network. In this setting, we seek to learn a semantic segmentation model from just weak image-level labels. The model is trained end-to-end to jointly optimize the representation while disambiguating the pixel-image label assignment. Fully convolutional training accepts inputs of any size, does not need object proposal pre-processing, and offers a pixelwise loss map for selecting latent instances. Our multi-class MIL loss exploits the further supervision given by images with multiple labels. We evaluate this approach through preliminary experiments on the PASCAL VOC segmentation challenge.
@inproceedings{pathakICLR15,
Author = {Pathak, Deepak and
Shelhamer, Evan and
Long, Jonathan and
Darrell, Trevor},
Title = {Fully Convolutional
Multi-Class Multiple Instance
Learning},
Booktitle = {ICLR Workshop},
Year = {2015}
}
|
 |
pdf |
abstract |
bibtex |
arXiv
Convolutional Neural Networks (CNNs) have recently emerged as the dominant model in computer vision. If provided with enough training data, they predict almost any visual quantity. In a discrete setting, such as classification, CNNs are not only able to predict a label but often predict a confidence in the form of a probability distribution over the output space. In continuous regression tasks, such a probability estimate is often lacking. We present a regression framework which models the output distribution of neural networks. This output distribution allows us to infer the most likely labeling following a set of physical or modeling constraints. These constraints capture the intricate interplay between different input and output variables, and complement the output of a CNN. However, they may not hold everywhere. Our setup further allows to learn a confidence with which a constraint holds, in the form of a distribution of the constrain satisfaction. We evaluate our approach on the problem of intrinsic image decomposition, and show that constrained structured regression significantly increases the state-of-the-art.
@inproceedings{pathakArxiv15,
Author = {Pathak, Deepak and
Kr\"ahenb\"uhl, Philipp and
Yu, Stella X. and
Darrell, Trevor},
Title = {Constrained Structured
Regression with Convolutional
Neural Networks},
Booktitle = {arXiv:1511.07497},
Year = {2015}
}
|
 |
pdf |
abstract |
bibtex
Topic-models for video analysis have been used for unsupervised identification of normal activity in videos, thereby enabling the detection of anomalous actions. However, while intervals containing anomalies are detected, it has not been possible to localize the anomalous activities in such models. This is a challenging problem as the abnormal content is usually a small fraction of the entire video data and hence distinctions in terms of likelihood are unlikely. Here we propose a methodology to extend the topic based analysis with rich local descriptors incorporating quantized spatio-temporal gradient descriptors with image location and size information. The visual clips over this vocabulary are then represented in latent topic space using models like pLSA. Further, we introduce an algorithm to quantify the anomalous content in a video clip by projecting the learned topic space information. Using the algorithm, we detect whether the video clip is abnormal and if positive, localize the anomaly in spatio-temporal domain. We also contribute one real world surveillance video dataset for comprehensive evaluation of the proposed algorithm. Experiments are presented on the proposed and two other standard surveillance datasets.
@inproceedings{pathakWACV15,
Author = {Pathak, Deepak and
Sharang, Abhijit and
Mukerjee, Amitabha},
Title = {Anomaly Localization
in Topic-based Analysis of
Surveillance Videos},
Booktitle = {WACV},
Year = {2015}
}
|
 |
pdf |
abstract |
bibtex
One of the interesting applications of computer vision is to be able to identify or detect persons in real world. This problem has been posed in the context of identifying people in television series or in multi-camera networks. However, a common scenario for this problem is to be able to identify people among images prevalent on social networks. In this paper we present a method that aims to solve this problem in real world conditions where the person can be in any pose, profile and orientation and the face itself is not always clearly visible. Moreover, we show that the problem can be solved with as weak supervision only a label whether the person is present or not, which is usually the case as people are tagged in social networks. This is challenging as there can be ambiguity in association of the right person. The problem is solved in this setting using a latent max-margin formulation where the identity of the person is the latent parameter that is classified. This framework builds on other off the shelf computer vision techniques for person detection and face detection and is able to also account for inaccuracies of these components. The idea is to model the complete person in addition to face, that too with weak supervision. We also contribute three real-world datasets that we have created for extensive evaluation of the solution. We show using these datasets that the problem can be effectively solved using the proposed method.
@inproceedings{pathakFG15,
Author = {Pathak, Deepak and
Satyavolu, Sai Nitish and
Namboodiri, Vinay P.},
Title = {Where is my Friend? -
Person identification in Social
Networks},
Booktitle = {Automatic Face and
Gesture Recognition (FG)},
Year = {2015}
}
|
 |
pdf |
abstract |
bibtex |
predictions2014 |
predictions2016
We compare Oscar forecasts derived from four data types (fundamentals, polling, prediction markets, and domain experts) across three attributes (accuracy, timeliness and cost effectiveness). Fundamentals-based forecasts are relatively expensive to construct, an attribute the academic literature frequently ignores, and update slowly over time, constraining their accuracy. However, fundamentals provide valuable insights into the relationship between key indicators for nominated movies and their chances of victory. For instance, we find that the performance in other awards shows is highly predictive of the Oscar victory whereas box office results are not. Polling- based forecasts have the potential to be both accurate and timely. Timeliness requires incentives for frequent responses by high-information users. Accuracy is achieved by a proper transformation of raw polls. Prediction market prices are accurate forecasts, but can be further improved by simple transformations of raw prices, yielding the most accurate forecasts in our study. Expert forecasts exhibit some characteristics of fundamental models, but are generally not comparatively accurate or timely. This study is unique in both comparing and aggregating four traditional data sources, and considering critical attributes beyond accuracy. We believe that the results of this study generalize to many other domains.
@inproceedings{pathakJPM15,
Author = {Pathak, Deepak and
Rothschild, David and
Dudik, Miro},
Title = {A Comparison Of Forecasting
Methods: Fundamentals, Polling,
Prediction Markets, and Experts},
Booktitle = {Journal of Prediction Markets (JPM)},
Year = {2015}
}
|
Modified version of template from here |